社会影响与伦理风险
数据批次: 0
新闻区域: 国内新闻
新闻数量: 21
新闻 1: 警惕!别让那些暴力、低俗的“外国山海经”在不知不觉中侵占了孩子的大脑!
来源: 微信 - 自媒体
主题: AI生成内容对青少年价值观和传统文化传承的负面影响及伦理风险
摘要:
新闻指出,由AI生成的暴力、低俗“外国山海经”动画形象在青少年中流行,成为其社交密码。文章担忧这些“低俗猎奇”内容正“侵占了孩子的大脑”,逐步“侵蚀着优秀传统文化的传承”,并可能导致青少年形成“经典可以随意篡改”的“错误认知”。作者呼吁家长和教育者应积极引导孩子辨别是非,抵制AI技术带来的负面文化影响,保护青少年价值观。
分析:
它明确指出“AI魔改生成”的“暴力、低俗”内容正在“侵占了孩子的大脑”,并“逐步侵蚀着优秀传统文化的传承”,可能在青少年心中埋下“经典可以随意篡改”的“错误认知”。这直接涉及了AI技术对社会伦理和青少年价值观塑造的负面“社会影响与伦理风险”,符合高价值标准。
正文:
睡前,喔喔说今天不听故事,想和我聊聊天,聊天的主题是“外国的山海经”。他说,班上很多男同学课后都在聊这个,动不动就“呼啦呼啦轰轰轰”,像在念神秘咒语一样,他很好奇,所以想让我和他说说。我一听很纳闷,外国的山海经,我怎么从来没听说过呀?
“你知道《山海经》吗?”我问。他说,“知道啊,就是里面有很多古老的神话故事,比如精卫填海,夸父逐日之类的。”我又问:“那外国的山海经也是国外的古老神话吗?”他回答,“不是的,它是很多奇怪的东西组合的,我就记得他们说过的一个鳄鱼头轰炸机。”
哦,我还真是孤陋寡闻了?赶紧上网一搜,果然,一堆的图片,还配了发音。“通通通通撒呼啦”,是长得像木棍的“木棍人”,“哩哩哩辣力辣”,是仙人掌大象,还有穿耐克鞋的鲨鱼、住在香蕉里的猴子……都是AI魔改生成的动画形象。
(图源
)
这些长相奇特的AI动物角色其实是“舶来品”,在国外火了后传到国内,被网友们参照《山海经》给它们编了图鉴,叫“外国山海经”。说实话,这些将毫不相干元素强行拼凑出的怪异形象毫无美感,相关视频更是造型诡异,夹杂不少暴力、血腥词汇和内容,让人非常不适。
这样的内容为什么会成为孩子们新的社交密码?我想,还是因为青少年猎奇、求新、被认可的心理。看到不一样的形象,听到不一样的声音,就会不由自主被吸引。一部分接触网络世界更没有约束的孩子,率先发现这些新大陆,为了体现自己的与众不同,又将这些拿来炫耀。其他孩子为了不被孤立,不被嘲笑,又纷纷跟风……
“挖自己的眼珠子然后吃掉”,“高空坠落后一地残肢断臂”,“白雪公主怀孕”……这种AI魔改将“低俗猎奇”包装为“趣味创新”,在不知不觉中逐步侵蚀着优秀传统文化的传承。青少年的辨别能力还不成熟,他们不一定理解这些图片的意思,却会跟风模仿,从而破坏心目中对“真善美”的理解,甚至可能在他们心中埋下“经典可以随意篡改”“历史可以肆意戏说”的错误认知。
虽然说文化应该多一些包容性,尤其是当下的AI热,打破了人们很多的传统思维,让创新变得无处不在也无比容易,我们也不妨对此类青少年亚文化多一些理解。但是,包容不同的文化并不意味着也要接纳那些血腥暴力、恶搞低俗的内容,更不意味着可以接受利用AI技术颠覆性改编。想一想,如果有一天当我们聊起中华传统典籍《山海经》,孩子们脑海中浮现的却是那些胡乱拼凑的怪异形象,这是多么令人痛心又悲哀的事!
想起前段时间被全网点赞的那位老师。当学生们在课堂上满口“包的”“666”等网络热梗时,老师没有纵容,没有充耳不闻,也没有简单粗暴地制止,而是耐心引导:“包的,666那种话……你脑子里其他的优美的、好的语言,都被覆盖了。”“喜欢说这些话是偷懒的表现,一说就会停止思考。”“当需要表达‘这个事情能不能做好’时,可以说‘我很有信心’‘……
这样的引导,既让学生们在深入思考中领略汉语言文字之美,又让他们认识到什么是“网络烂梗”,帮助他们分辨网络与现实,鼓励他们不盲从、不跟风,做真实而独特的自己。
“外国的山海经”这事也一样。我们没办法让孩子生活在真空里,隔绝一切不健康的事物,也不能一听孩子说这些就火冒三丈,劈头盖脸一顿骂,更不能无所谓,听之任之,认为没必要上纲上线,这不过是孩子们之间的一个游戏。最好的方法,就是引导他多接触正确、美好的事物,不断增强辨别是非美丑的能力。
于是,我们一起看了网上搜来的“外国山海经”的图片和一小段动画,又和他重温了一遍“精卫填海”“夸父逐日”的经典神话,然后问他,觉得中国和外国的山海经有什么不同?
喔喔说,“中国的神话语言很优美,而且都藏着道理。比如精卫鸟和夸父,都体现了勇敢、顽强、坚持不懈、契而不舍的精神;外国的山海经,都是硬凑出来的图片,看得不舒服,比如那个仙人掌大象,看得我起鸡皮疙瘩,而且语言也毫无意义,就是轰轰轰,啦啦啦这样的。我觉得还是中国的《山海经》好看。”
“可班上的同学都在聊这个,你怎么办呢?”我问。喔喔回答:“我会把今天看到的、想到的说给他们听,告诉他们中国有很多美好的故事,比那些乱七八糟的强多了!”又给我提要求,“妈妈,你把这件事写一下吧,还要发给家长看,让大家都知道这个危害。”
于是,有了这篇命题作文。我们并不反对孩子接触多种多样的文化,但我们应该感到担忧的是,如果孩子满脑子都是那些舶来文化时,那确实是一件非常值得警惕的事。您认为呢?
主题分类:
社会影响与伦理风险
新闻 2: arXiv 每日论文 20251218 | 计算机视觉
来源: 微信 - 自媒体
主题: 计算机视觉前沿研究:AI安全、可靠性与伦理挑战应对
摘要:
本期arXiv计算机视觉论文集涵盖了多项前沿研究,其中多篇论文聚焦于AI的安全性、可靠性与伦理问题。具体包括AI生成内容(如深度伪造图像和视频)的检测技术、医学AI模型的鲁棒性与公平性评估,以及人脸隐私保护等关键领域,旨在应对AI技术发展带来的潜在风险。
分析:
该新闻具有高价值。多篇论文直接涉及“社会影响与伦理风险”等高价值标准。例如,[new 023]关注医学图像疾病分类中“视觉-语言模型在交叉人口亚组中存在的诊断置信度偏差问题”,旨在提升“交叉公平性”,直接应对“算法歧视”和“偏见”。[new 026]和[new 036]分别研究“人脸模板逆向攻击”和“婴儿视频中人脸匿名化”,旨在解决“隐私泄露”问题。此外,[new 015]和[replaced 027]关注医学AI的“鲁棒性”和“幻觉性切片伪影”以及“Sycophancy”问题,这些都可能导致AI“误操作”或“信任危机”,对社会产生负面影响。同时,[new 009]、[new 014]和[new 027]提出的“图像篡改检测”和“AI生成视频检测”技术,虽然也与“政治与意识形态安全”相关,但其更广泛的意义在于维护社会信任和信息真实性,亦可归入广义的社会伦理范畴。
正文:
为方便阅读,详细内容已同步 github 仓库,欢迎 star~
https://github.com/advanced-cs/arXiv_daily
cs.CV
最新发布:109 篇
更新:58 篇
最新发布:
[new 001] IMKD: Intensity-Aware Multi-Level Knowledge Distillation for Camera-Radar Fusion
简介: 该论文面向雷达-相机融合的3D目标检测任务,解决现有知识蒸馏方法破坏模态特性的缺陷。提出IMKD框架,通过三阶段强度感知的多级知识蒸馏,在不依赖LiDAR推理的前提下,保留各传感器特性并增强互补性,显著提升性能。
链接:
https://arxiv.org/pdf/2512.15581v1
备注: Accepted at IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2026. 22 pages, 8 figures. Includes supplementary material
[new 002] IC-Effect: Precise and Efficient Video Effects Editing via In-Context Learning
简介: 该论文提出IC-Effect,面向视频VFX编辑任务,解决少样本下特效注入难、背景保真差、时序不一致等问题。工作包括:基于DiT的上下文学习框架、两阶段训练(通用适配+Effect-LoRA)、时空稀疏令牌化,并发布15种风格的配对数据集。
链接:
https://arxiv.org/pdf/2512.15635v1
[new 003] Improving VQA Reliability: A Dual-Assessment Approach with Self-Reflection and Cross-Model Verification
简介: 该论文面向视觉问答(VQA)任务,旨在解决视觉语言模型(VLM)易幻觉、答案不可靠的问题。提出DAVR框架,融合自省评估与跨模型验证双路径,实现更准确实时的不确定性估计,显著提升VQA答案可信度。
链接:
https://arxiv.org/pdf/2512.14770v1
[new 004] The LUMirage: An independent evaluation of zero-shot performance in the LUMIR challenge
简介: 该论文属医学图像配准任务,旨在检验深度学习方法在LUMIR挑战中宣称的零样本泛化能力。作者独立复现评估,发现模型在T1w数据上表现良好,但在跨模态(T2等)、高分辨率及不同预处理下性能显著下降,揭示其零样本能力被高估,强调需更贴近临床的实际评估协议。
链接:
https://arxiv.org/pdf/2512.15505v1
[new 005] In Pursuit of Pixel Supervision for Visual Pre-training
简介: 该论文属视觉自监督预训练任务,旨在探索像素级监督的有效性。针对现有方法多依赖latent空间的问题,提出Pixio模型——增强型掩码自编码器,通过更难的重建任务和强架构,在20亿图像上自监督训练,显著提升深度估计、3D重建等下游性能,证明像素空间学习是latent方法的有力替代与补充。
链接:
https://arxiv.org/pdf/2512.15715v1
备注: Project page:
https://github.com/facebookresearch/pixio
[new 006] Towards Physically-Based Sky-Modeling For Image Based Lighting
简介: 该论文属图像生成与物理光照建模任务,旨在解决现有DNN天空模型无法兼顾光度真实性与全动态范围(22 f-stops)的问题。作者提出AllSky——首个直接从实拍HDR数据学习的全天气物理天空模型,支持用户控太阳/云位置,并建立新评估标准验证其不可替代性。
链接:
https://arxiv.org/pdf/2512.15632v1
[new 007] PMMD: A pose-guided multi-view multi-modal diffusion for person generation
简介: 该论文属人物图像生成任务,旨在解决多视角下姿态控制难、服饰失真与遮挡等问题。提出PMMD扩散模型,融合多视角图像、姿态图和文本提示,设计多模态编码器、ResCVA模块及跨模态融合机制,提升身份一致性、细节与可控性。
链接:
https://arxiv.org/pdf/2512.15069v1
[new 008] Uni-Parser Technical Report
简介: 该论文提出Uni-Parser,一种面向科技文献与专利的工业级多模态文档解析引擎。旨在解决传统流水线方法跨模态对齐差、扩展难、吞吐低等问题,通过多专家模块化架构、动态调度与GPU优化,实现高精度、高吞吐、低成本的大规模PDF解析。
链接:
https://arxiv.org/pdf/2512.15098v1
[new 009] VAAS: Vision-Attention Anomaly Scoring for Image Manipulation Detection in Digital Forensics
简介: 该论文面向数字取证中的图像篡改检测任务,旨在解决AI生成伪造图像难识别、缺乏可量化异常强度的问题。提出VAAS框架:融合ViT全局注意力异常估计与SegFormer补丁级自一致性评分,输出连续、可解释的定位与强度联合异常分。
链接:
https://arxiv.org/pdf/2512.15512v1
[new 010] Expand and Prune: Maximizing Trajectory Diversity for Effective GRPO in Generative Models
简介: 该论文面向生成模型对齐任务,解决GRPO中大组采样与高计算成本的矛盾。提出Pro-GRPO框架:通过潜空间轨迹动态剪枝(早停奖励聚集轨迹),结合“扩展—剪枝”策略,在提升轨迹多样性的同时显著降低计算开销。
链接:
https://arxiv.org/pdf/2512.15347v1
备注: 10 pages, 5 figures
[new 011] DiffusionVL: Translating Any Autoregressive Models into Diffusion Vision Language Models
简介: 该论文提出DiffusionVL,将现有自回归(AR)多模态模型转化为扩散式视觉语言模型(dVLM)。旨在解决dVLM性能落后于AR模型的问题,通过轻量微调实现范式迁移,支持任意长度生成与KV缓存复用,显著提升性能与推理速度。
链接:
https://arxiv.org/pdf/2512.15713v1
备注: 11 pages, 5 figures, conference or other essential info
[new 012] MMMamba: A Versatile Cross-Modal In Context Fusion Framework for Pan-Sharpening and Zero-Shot Image Enhancement
简介: 该论文面向遥感图像融合任务,解决传统方法在泛化性与计算效率上的不足。提出MMMamba框架,基于Mamba架构与多模态交错扫描机制,实现跨模态上下文融合,支持全色锐化与零样本图像增强。
链接:
https://arxiv.org/pdf/2512.15261v1
备注: \link{Code}{
https://github.com/Gracewangyy/MMMamba}
[new 013] TalkVerse: Democratizing Minute-Long Audio-Driven Video Generation
简介: 该论文面向音频驱动的长时 talking-video 生成任务,旨在解决现有方法依赖闭源数据、计算成本高、难以复现的问题。作者构建了开源大规模数据集 TalkVerse(230 万片段),并提出轻量级 5B DiT 基线模型,支持分钟级生成、零-shot 拍摄与语音重配音,显著降低推理开销。
链接:
https://arxiv.org/pdf/2512.14938v1
备注: open-sourced single-person full-body talking video generation dataset, training code and checkpoints
[new 014] Where is the Watermark? Interpretable Watermark Detection at the Block Level
简介: 该论文属于图像水印检测任务,旨在解决现有水印方法缺乏可解释性、无法定位水印位置的问题。作者提出一种后处理式块级可解释水印方法,基于小波域统计嵌入,生成可视化检测图,兼顾鲁棒性、不可感知性与区域级可解释性。
链接:
https://arxiv.org/pdf/2512.14994v1
备注: 20 pages, 14 figures. Camera-ready for WACV 2026
[new 015] PANDA-PLUS-Bench: A Clinical Benchmark for Evaluating Robustness of AI Foundation Models in Prostate Cancer Diagnosis
简介: 该论文面向前列腺癌Gleason分级任务,旨在解决AI模型依赖幻觉性切片伪影而非真实生物特征导致临床鲁棒性差的问题。作者构建了PANDA-PLUS-Bench基准数据集,评估7个基础模型对滑片混淆因素的鲁棒性,并开源评测工具。
链接:
https://arxiv.org/pdf/2512.14922v1
备注: 21 pages, 5 figures, 6 Tables
[new 016] MECAD: A multi-expert architecture for continual anomaly detection
简介: 该论文提出MECAD,一种面向持续异常检测的多专家架构。旨在解决工业场景中产品类别动态增加导致的知识遗忘问题,通过特征相似性动态分配专家、优化核心集选择与重放缓冲机制,实现增量学习,避免全模型重训练,兼顾效率与知识保留。
链接:
https://arxiv.org/pdf/2512.15323v1
备注: Accepted to ICIAP 2025
[new 017] Prototypical Learning Guided Context-Aware Segmentation Network for Few-Shot Anomaly Detection
简介: 该论文面向少样本异常检测(FSAD)任务,旨在解决预训练特征与目标场景间域差距导致的检测性能下降问题。提出PCSNet模型,包含原型特征适配(PFA)和上下文感知分割(CAS)子网络,通过原型引导、像素级差异损失和伪异常训练提升特征判别力与定位精度。
链接:
https://arxiv.org/pdf/2512.15319v1
[new 018] Explainable Action Form Assessment by Exploiting Multimodal Chain-of-Thoughts Reasoning
简介: 该论文提出人类动作形态评估(AFA)新任务,旨在解决动作标准化程度评估与可解释反馈缺失问题。构建多模态链式思维数据集CoT-AFA,提出Explainable Fitness Assessor框架,融合视觉与语义信息,实现动作判别、原因解释与改进建议一体化。
链接:
https://arxiv.org/pdf/2512.15153v1
[new 019] Vibe Spaces for Creatively Connecting and Expressing Visual Concepts
简介: 该论文提出“Vibe Blending”新任务,旨在生成视觉概念的创意融合体。针对现有方法难以在非线性潜空间中识别并遍历远距概念间共享语义(即“vibe”)的问题,作者构建了分层图流形“Vibe Space”,在CLIP等特征空间中学习低维测地线路径,并设计融合人类判断、LLM推理与几何难度评分的评估框架。
链接:
https://arxiv.org/pdf/2512.14884v1
备注: Project page:
https://huzeyann.github.io/VibeSpace-webpage/
[new 020] Is Nano Banana Pro a Low-Level Vision All-Rounder? A Comprehensive Evaluation on 14 Tasks and 40 Datasets
简介: 该论文评估商用文生图模型Nano Banana Pro能否作为低-level视觉通用求解器。针对14类任务、40个数据集开展零样本评测,发现其主观视觉质量优于专用模型,但定量指标落后,主因生成随机性导致像素一致性不足。
链接:
https://arxiv.org/pdf/2512.15110v1
备注: Technical Report; 65 Pages, 36 Figures, 17 Tables; Poject Page:
https://lowlevelbanana.github.io/
[new 021] Multi-View Foundation Models
简介: 该论文提出多视图基础模型,解决单图基础模型在多视图下特征不一致问题。通过在Transformer模型(如DINO、SAM、CLIP)中引入3D感知注意力层,实现跨视图对应点的特征一致性,无需显式3D重建,直接在图像空间优化,提升表面法向估计与多视图分割性能。
链接:
https://arxiv.org/pdf/2512.15708v1
[new 022] Evaluation of deep learning architectures for wildlife object detection: A comparative study of ResNet and Inception
简介: 该论文属野生动物目标检测任务,旨在解决环境多变、物种相似及类内差异大导致的检测难题。研究对比ResNet-101与Inception v3在统一预处理和数据划分下的性能,评估其准确率与mAP,并分析优劣与局限。
链接:
https://arxiv.org/pdf/2512.15480v1
[new 023] Intersectional Fairness in Vision-Language Models for Medical Image Disease Classification
简介: 该论文面向医学图像疾病分类任务,解决视觉-语言模型在交叉人口亚组(如年龄、性别、种族组合)中存在的诊断置信度偏差问题。提出无需敏感属性推理的CMAC-MMD训练框架,提升交叉公平性与整体诊断精度。
链接:
https://arxiv.org/pdf/2512.15249v1
[new 024] Towards Seamless Interaction: Causal Turn-Level Modeling of Interactive 3D Conversational Head Dynamics
简介: 该论文属3D对话头动生成任务,旨在解决现有方法忽略对话轮次因果性、导致时序不连贯的问题。提出TIMAR框架:基于因果的轮次级掩码自回归建模,融合音视频上下文,用轻量扩散头预测连续3D头动,显著提升生成质量与泛化性。
链接:
https://arxiv.org/pdf/2512.15340v1
[new 025] Isolated Sign Language Recognition with Segmentation and Pose Estimation
简介: 该论文面向孤立手语识别(ISLR)任务,旨在解决ASL识别中数据稀缺、 signer差异大、计算成本高的问题。提出融合姿态估计、关键区域分割与ResNet-Transformer联合建模的方法,在降低计算开销的同时提升对 signer 变异的鲁棒性。
链接:
https://arxiv.org/pdf/2512.14876v1
备注: 5 pages, 3 Figures
[new 026] CLIP-FTI: Fine-Grained Face Template Inversion via CLIP-Driven Attribute Conditioning
简介: 该论文属人脸模板逆向攻击任务,旨在从泄露的识别模板重建高保真、细粒度人脸图像。针对现有方法面部部件模糊、迁移性差的问题,提出CLIP-FTI:利用CLIP提取面部属性语义嵌入,通过跨模态交互融合模板并驱动StyleGAN生成更真实、可迁移的重建结果。
链接:
https://arxiv.org/pdf/2512.15433v1
备注: Accepted by AAAI 2026
[new 027] Skyra: AI-Generated Video Detection via Grounded Artifact Reasoning
简介: 该论文面向AI生成视频检测任务,旨在解决现有方法缺乏可解释性的问题。提出Skyra模型,通过识别视觉伪影实现检测与解释;构建ViF-CoT-4K数据集和ViF-Bench基准;采用两阶段训练提升时空感知与推理能力。
链接:
https://arxiv.org/pdf/2512.15693v1
备注: Project Page:
https://github.com/JoeLeelyf/Skyra
[new 028] Step-GUI Technical Report
简介: 该论文面向GUI自动化任务,解决高质量训练数据获取成本高、标注可靠性低的问题。提出自进化训练流水线(含校准步奖励系统)和Step-GUI模型,构建隐私优先的GUI-MCP协议,并发布真实场景基准AndroidDaily。
链接:
https://arxiv.org/pdf/2512.15431v1
备注: 41 pages, 26 figures
[new 029] Emotion Recognition in Signers
简介: 该论文属多模态情感识别任务,旨在解决手语者情感识别中语法与情感面部表达重叠、数据稀缺两大挑战。作者构建日语手语数据集eJSL,结合英手语数据集BOBSL,提出跨语言方法,验证文本情绪识别迁移、时序片段选择及手部运动建模的有效性,并建立强基线。
链接:
https://arxiv.org/pdf/2512.15376v1
[new 030] MVGSR: Multi-View Consistent 3D Gaussian Super-Resolution via Epipolar Guidance
简介: 该论文面向3D高斯泼溅(3DGS)超分辨率任务,解决低分辨率输入导致高分辨率渲染质量差、跨视图不一致的问题。提出MVGSR框架:基于相机位姿的辅助视图选择方法,以及首创的极线约束多视图注意力机制,提升几何一致性与细节保真度。
链接:
https://arxiv.org/pdf/2512.15048v1
备注: 9 pages, 7 figures
[new 031] ERIENet: An Efficient RAW Image Enhancement Network under Low-Light Environment
简介: 该论文属低光RAW图像增强任务,旨在解决现有方法串行处理多尺度信息导致模型重、速度慢,且忽视绿色通道优势的问题。提出ERIENet:采用全并行多尺度架构与绿通道引导分支,提升效率与重建质量,达146+ FPS(4K)。
链接:
https://arxiv.org/pdf/2512.15186v1
备注: 5 pages, 4 figures, conference ICVISP
[new 032] DeX-Portrait: Disentangled and Expressive Portrait Animation via Explicit and Latent Motion Representations
简介: 该论文属人脸动画任务,旨在解决单图+驱动视频生成中头姿与表情难以解耦控制的问题。提出DeX-Portrait方法:显式建模姿态(全局变换)、隐式编码表情(latent code),通过双分支条件注入与交叉注意力实现解耦驱动,并引入渐进式混合CFG提升身份一致性。
链接:
https://arxiv.org/pdf/2512.15524v1
备注: Projectpage:
https://syx132.github.io/DeX-Portrait/
[new 033] 3DProxyImg: Controllable 3D-Aware Animation Synthesis from Single Image via 2D-3D Aligned Proxy Embedding
简介: 该论文属单图像3D动画生成任务,旨在解决现有方法在渲染质量与3D可控性间的权衡困境。提出3DProxyImg框架,通过2D-3D对齐的代理表示解耦几何控制与外观合成,实现轻量、可控、高保真的3D-aware动画生成。
链接:
https://arxiv.org/pdf/2512.15126v1
[new 034] A Masked Reverse Knowledge Distillation Method Incorporating Global and Local Information for Image Anomaly Detection
简介: 该论文面向图像异常检测任务,旨在解决知识蒸馏方法易过泛化的问题。提出掩码反向知识蒸馏(MRKD),通过图像级和特征级掩码,将重建转为恢复,融合全局与局部信息,提升上下文建模能力并抑制过泛化。
链接:
https://arxiv.org/pdf/2512.15326v1
[new 035] SMART: Semantic Matching Contrastive Learning for Partially View-Aligned Clustering
简介: 该论文面向部分视图对齐聚类(PVC)任务,解决未对齐数据语义利用不足及跨视图分布偏移导致匹配不准的问题。提出SMART模型,通过语义匹配对比学习缓解分布偏移,统一建模对齐与未对齐样本,提升多视图聚类性能。
链接:
https://arxiv.org/pdf/2512.15396v1
[new 036] BLANKET: Anonymizing Faces in Infant Video Recordings
简介: 该论文提出BLANKET方法,解决婴儿视频中人脸匿名化任务:在保护隐私(去标识化)的同时,保留面部关键属性与表情时序一致性。工作包括基于扩散模型的随机脸生成与时空一致的换脸融合,并在婴儿视频数据集上验证其优于DeepPrivacy2。
链接:
https://arxiv.org/pdf/2512.15542v1
备注: Project website:
https://github.com/ctu-vras/blanket-infant-face-anonym
[new 037] EmoCaliber: Advancing Reliable Visual Emotion Comprehension via Confidence Verbalization and Calibration
简介: 该论文面向视觉情感理解(VEC)任务,解决现有MLLMs将情感预测视为确定性问题、忽视情感主观性与多义性的缺陷。提出EmoCaliber模型,通过三阶段训练实现信心口头化与校准,提升预测可靠性与可解释性。
链接:
https://arxiv.org/pdf/2512.15528v1
[new 038] See It Before You Grab It: Deep Learning-based Action Anticipation in Basketball
简介: 该论文提出篮球视频中的动作预判任务,聚焦于投篮后哪队将获得球权(即篮板归属)的提前预测。作者构建了含10万片段、300小时视频及2000+标注篮板事件的新数据集,并基于深度学习方法开展基准实验,同时拓展至篮板分类与定位任务。
链接:
https://arxiv.org/pdf/2512.15386v1
[new 039] Null-LoRA: Low-Rank Adaptation on Null Space
简介: 该论文属参数高效微调任务,旨在解决大模型微调冗余高、参数效率低的问题。提出Null-LoRA方法,将低秩增量更新约束于预训练模型的非平凡零空间内,冻结部分低秩矩阵以减少冗余、提升有效秩,在图像-文本检索和视觉问答任务上以更少参数超越现有方法。
链接:
https://arxiv.org/pdf/2512.15233v1
[new 040] The Renaissance of Expert Systems: Optical Recognition of Printed Chinese Jianpu Musical Scores with Lyrics
简介: 该论文属光学音乐识别(OMR)任务,旨在解决中文简谱(含歌词)的自动识别难题。提出一种无需大量标注数据的模块化专家系统,融合传统计算机视觉与无监督深度学习,实现简谱到MusicXML/MIDI的高精度转换。
链接:
https://arxiv.org/pdf/2512.14758v1
备注: 13 pages, 12 figures
[new 041] End-to-End Training for Autoregressive Video Diffusion via Self-Resampling
简介: 该论文面向自回归视频扩散建模任务,旨在解决训练与推理不匹配导致的暴露偏差问题。提出教师无关的端到端训练框架Resampling Forcing,通过自采样模拟历史帧错误、稀疏因果掩码保持时序因果性,并引入无参历史路由机制提升长视频生成一致性。
链接:
https://arxiv.org/pdf/2512.15702v1
备注: Project Page:
https://guoyww.github.io/projects/resampling-forcing/
[new 042] Preserving Marker Specificity with Lightweight Channel-Independent Representation Learning
简介: 该论文属多路组织成像的自监督表征学习任务,旨在解决早期通道融合模型丢失标记特异性信息的问题。作者提出轻量级通道独立模型CIM-S,通过分离通道与浅层架构保留标记特异性,在Hodgkin淋巴瘤数据上验证其在罕见细胞判别等任务中优于大模型。
链接:
https://arxiv.org/pdf/2512.15410v1
备注: 16 pages, 9 figures, MIDL 2026 conference
[new 043] Adaptive Multimodal Person Recognition: A Robust Framework for Handling Missing Modalities
简介: 该论文面向多模态人物识别任务,解决现实场景中模态缺失或退化导致性能下降的问题。提出自适应三模态框架,融合语音、人脸、手势,采用多任务学习、跨模态注意力与置信度加权融合,显著提升缺失模态下的鲁棒性与准确率。
链接:
https://arxiv.org/pdf/2512.14961v1
备注: 10 pages and 8 tables
[new 044] Borrowing from anything: A generalizable framework for reference-guided instance editing
简介: 该论文面向参考引导的实例编辑任务,旨在解决语义纠缠问题——即参考图像的内在外观与外在属性难以分离。提出GENIE框架,含空间对齐、自适应残差缩放和渐进注意力融合模块,实现显式解耦与精准外观迁移。
链接:
https://arxiv.org/pdf/2512.15138v1
备注: 5 pages
[new 045] VTCBench: Can Vision-Language Models Understand Long Context with Vision-Text Compression?
简介: 该论文提出VTCBench基准,评估视觉语言模型(VLMs)在视觉-文本压缩(VTC)下的长上下文理解能力。针对VTC虽提升效率但损害长程依赖建模的问题,设计三大任务:检索、推理与记忆,并评测主流模型,揭示其在VTC下长上下文理解显著退化。
链接:
https://arxiv.org/pdf/2512.15649v1
[new 046] Beyond Proximity: A Keypoint-Trajectory Framework for Classifying Affiliative and Agonistic Social Networks in Dairy Cattle
简介: 该论文属行为识别任务,旨在解决奶牛社交行为(亲和/对抗)自动分类难题。提出基于关键点轨迹的框架,用姿态动态特征替代静态距离阈值,结合YOLOv11、ByteTrack、ZebraPose等实现端到端分析,在商业牧场数据上达77.51%准确率。
链接:
https://arxiv.org/pdf/2512.14998v1
备注: 36 pages, 12 figures, 8 tables
[new 047] Model Agnostic Preference Optimization for Medical Image Segmentation
简介: 该论文面向医学图像分割任务,解决现有偏好优化方法模型依赖性强、预测多样性不足的问题。提出模型无关的偏好优化框架MAPO,利用Dropout生成随机分割假设构建无真值监督的偏好一致梯度,支持2D/3D CNN与Transformer架构。
链接:
https://arxiv.org/pdf/2512.15009v1
[new 048] Spatia: Video Generation with Updatable Spatial Memory
简介: 该论文属视频生成任务,旨在解决长时空间-时间一致性差的问题。提出Spatia框架,以可更新的3D点云作为空间记忆,结合视觉SLAM动态更新,实现动态-静态解耦,提升一致性,并支持相机控制与3D交互编辑。
链接:
https://arxiv.org/pdf/2512.15716v1
备注: Project page:
https://zhaojingjing713.github.io/Spatia/
[new 049] An Efficient and Effective Encoder Model for Vision and Language Tasks in the Remote Sensing Domain
简介: 该论文面向遥感领域的视觉-语言任务,旨在解决大模型参数多、计算成本高的问题。提出轻量级编码器-only模型GeoMELT,统一支持图像到文本生成与跨模态检索,兼顾高效性与多任务性能。
链接:
https://arxiv.org/pdf/2512.15531v1
[new 050] From Camera to World: A Plug-and-Play Module for Human Mesh Transformation
简介: 该论文属3D人体网格重建任务,旨在解决从单目图像恢复世界坐标系下准确人体网格时因相机旋转未知导致的误差问题。提出Mesh-Plug插件模块,利用RGB与深度图估计相机俯仰角,并联合优化根关节朝向与姿态,实现相机到世界坐标的精准转换。
链接:
https://arxiv.org/pdf/2512.15212v1
[new 051] TBC: A Target-Background Contrast Metric for Low-Altitude Infrared and Visible Image Fusion
简介: 该论文面向红外与可见光图像融合任务,解决低空无人机侦察中传统无参考评价指标(如熵、平均梯度)易将噪声误判为细节、导致“噪声陷阱”的问题;提出基于韦伯定律的Target-Background Contrast(TBC)指标,聚焦目标与背景相对对比度,抑制背景噪声、突出目标可见性。
链接:
https://arxiv.org/pdf/2512.15211v1
[new 052] Cross-modal ultra-scale learning with tri-modalities of renal biopsy images for glomerular multi-disease auxiliary diagnosis
简介: 该论文属医学图像多模态分类任务,旨在解决肾活检三模态(TEM、OM、IM)图像因纳米/微米尺度差异导致的特征融合难问题。提出CMUS-Net网络,含稀疏多实例学习、跨模态尺度注意力模块及多损失加权机制,实现IgAN、MN、LN等多病种精准辅助诊断。
链接:
https://arxiv.org/pdf/2512.15171v1
[new 053] Robust and Calibrated Detection of Authentic Multimedia Content
简介: 该论文属多媒体真实性检测任务,旨在解决现有深伪检测方法假阳性率高、易被对抗攻击的缺陷。作者提出校准式重合成框架,通过判断内容是否可被合理否认,实现高精度、低假阳、抗高效对抗攻击的真实性验证。
链接:
https://arxiv.org/pdf/2512.15182v1
[new 054] Robust Multi-view Camera Calibration from Dense Matches
简介: 该论文属多视图几何任务,旨在提升强径向畸变相机的鲁棒标定与位姿估计。针对SfM流程,提出两项改进:(1)优化密集匹配点的子采样策略;(2)设计增量式视图添加准则。实验表明其显著提升精度(79.9% vs 40.4%)。
链接:
https://arxiv.org/pdf/2512.15608v1
备注: This paper has been accepted for publication at the 21st International Conference on Computer Vision Theory and Applications (VISAPP 2026). Conference website:
https://visapp.scitevents.org
[new 055] EagleVision: A Dual-Stage Framework with BEV-grounding-based Chain-of-Thought for Spatial Intelligence
简介: 该论文提出EagleVision框架,解决空间智能中三维一致性弱、视角单一、推理链不可追溯等问题。它分两阶段:宏观感知(SPF-DPP选关键帧)和微观验证(BEV姿态查询+强化学习),实现可解释、可验证的空间链式推理。
链接:
https://arxiv.org/pdf/2512.15160v1
备注: 13 pages, 7 figures, 6 tables
[new 056] Puzzle Curriculum GRPO for Vision-Centric Reasoning
简介: 该论文属视觉语言模型(VLM)的强化学习后训练任务,旨在解决GRPO中依赖人工标注、奖励稀疏平坦、推理与答案不一致三大问题。提出无监督的Puzzle Curriculum GRPO(PC-GRPO),引入自监督拼图环境、难度感知课程学习和推理-答案一致性奖励机制,提升视觉推理质量与稳定性。
链接:
https://arxiv.org/pdf/2512.14944v1
备注: Project page:
https://pcgrpo.github.io
[new 057] Evaluating the Capability of Video Question Generation for Expert Knowledge Elicitation
简介: 该论文属视频问答中的视频问题生成(VQG)任务,旨在评估模型生成问题以有效激发专家隐性知识的能力。作者构建新数据集EgoExoAsk,提出基于问答检索的量化评估协议,验证模型上下文利用能力与问题启发性的正相关。
链接:
https://arxiv.org/pdf/2512.15006v1
备注: WACV 2026 accepted
[new 058] InpaintDPO: Mitigating Spatial Relationship Hallucinations in Foreground-conditioned Inpainting via Diverse Preference Optimization
简介: 该论文针对前景条件图像修复中前景与背景空间关系幻觉(如尺度、位置、视角不合理)问题,提出InpaintDPO框架。首创将DPO引入该任务,通过MaskDPO、条件非对称偏好优化和共享共性偏好优化,提升空间合理性与边界一致性。
链接:
https://arxiv.org/pdf/2512.15644v1
[new 059] Assessing the Visual Enumeration Abilities of Specialized Counting Architectures and Vision-Language Models
简介: 该论文属于视觉计数任务,旨在评估专用计数模型与多模态大模型(VLMs)在开放场景下的物体数量估计能力。研究对比二者在多个数据集上的性能,发现VLMs经中间表征提示后可媲美甚至超越专用模型,但仍难以应对复杂场景。
链接:
https://arxiv.org/pdf/2512.15254v1
[new 060] Stylized Synthetic Augmentation further improves Corruption Robustness
简介: 该论文属图像分类任务,旨在提升模型对常见图像腐蚀的鲁棒性。提出“风格化合成增强”方法:将神经风格迁移应用于合成图像,并系统分析其与规则增强(如TrivialAugment)的协同效应,在CIFAR-10-C等基准上达SOTA鲁棒精度。
链接:
https://arxiv.org/pdf/2512.15675v1
备注: Accepted at VISAPP 2026 conference
[new 061] Off The Grid: Detection of Primitives for Feed-Forward 3D Gaussian Splatting
简介: 该论文属3D场景重建任务,旨在解决传统前馈式3D高斯泼溅中像素对齐的刚性网格导致的原始体素分布粗糙、效率低、质量差问题。提出“离网”架构,通过多分辨率关键点式检测器自适应定位子像素级高斯原语,端到端自监督训练,显著提升渲染质量与效率。
链接:
https://arxiv.org/pdf/2512.15508v1
[new 062] GRAN-TED: Generating Robust, Aligned, and Nuanced Text Embedding for Diffusion Models
简介: 该论文面向文本到图像/视频扩散模型,解决文本编码器评估难、适配差的问题。提出TED-6K轻量文本基准用于高效评估,并设计两阶段训练范式(MLLM微调+层加权)构建更鲁棒、对齐、细腻的GRAN-TED文本编码器。
链接:
https://arxiv.org/pdf/2512.15560v1
[new 063] SynthSeg-Agents: Multi-Agent Synthetic Data Generation for Zero-Shot Weakly Supervised Semantic Segmentation
简介: 该论文提出SynthSeg-Agents,面向零样本弱监督语义分割(ZSWSSS)任务,旨在仅用图像级标签、无需任何真实图像即实现像素级分割。其通过LLM驱动的双智能体框架——自优化提示生成与VLM图像合成——全自动构建高质量合成训练数据,并经CLIP筛选与ViT重标注,实现无真实图像监督的端到端训练。
链接:
https://arxiv.org/pdf/2512.15310v1
[new 064] GateFusion: Hierarchical Gated Cross-Modal Fusion for Active Speaker Detection
简介: 该论文面向主动说话人检测(ASD)任务,旨在精准定位视频中每帧的说话人。针对 late fusion 忽视细粒度跨模态交互的问题,提出 GateFusion:基于分层门控跨模态融合(HiGate)的架构,并引入掩码对齐损失与过正惩罚两项辅助目标,显著提升多基准性能。
链接:
https://arxiv.org/pdf/2512.15707v1
备注: accepted by WACV 2026
[new 065] SkyCap: Bitemporal VHR Optical-SAR Quartets for Amplitude Change Detection and Foundation-Model Evaluation
简介: 该论文面向VHR SAR幅度变化检测(ACD)任务,解决SAR标注难、光学易受云干扰问题;构建首个光学-SAR四元组数据集SkyCap,提出光学到SAR标签迁移方法,并评估基础模型在ACD上的性能,发现光学模型经适配预处理可优于SAR专用模型。
链接:
https://arxiv.org/pdf/2512.14755v1
备注: 8 pages, 0 figures. Accepted at Advances in Representation Learning for Earth Observation (REO) at EurIPS 2025
[new 066] RUMPL: Ray-Based Transformers for Universal Multi-View 2D to 3D Human Pose Lifting
简介: 该论文属2D到3D人体姿态估计任务,旨在解决多视角下因遮挡、投影歧义及真实数据稀缺导致的泛化性差问题。提出RUMPL:基于射线的Transformer模型,用相机无关的3D射线表征2D关键点,支持任意多视角配置;引入视图融合Transformer提升一致性。
链接:
https://arxiv.org/pdf/2512.15488v1
[new 067] Persistent feature reconstruction of resident space objects (RSOs) within inverse synthetic aperture radar (ISAR) images
简介: 该论文属空间目标识别任务,旨在提升近地轨道空间物体(RSO)的态势感知能力。针对ISAR图像中结构特征易受噪声干扰、难以稳定检测的问题,提出基于梯度比边缘检测与双权重Hough变换的序列特征检测与跟踪方法,实现高精度线性结构重建与阴影等鲁棒特征识别。
链接:
https://arxiv.org/pdf/2512.15618v1
[new 068] AquaDiff: Diffusion-Based Underwater Image Enhancement for Addressing Color Distortion
简介: 该论文属于水下图像增强任务,旨在解决水下图像因光吸收与散射导致的色偏、低对比度和细节丢失问题。提出基于扩散模型的AquaDiff框架,融合色度先验引导的色彩补偿、跨注意力条件扩散及多分辨率特征提取,并设计跨域一致性损失优化增强效果。
链接:
https://arxiv.org/pdf/2512.14760v1
[new 069] Tracking spatial temporal details in ultrasound long video via wavelet analysis and memory bank
简介: 该论文面向超声长视频的器官/病灶分割与跟踪任务,旨在解决低对比度、噪声干扰导致的小目标丢失和边界模糊问题。提出基于小波分析与记忆库的网络MWNet,融合高频细节、多尺度频域特征,并利用跨注意力记忆机制实现长时序目标跟踪。
链接:
https://arxiv.org/pdf/2512.15066v1
备注: Chenxiao Zhang and Runshi Zhang contributed equally to this work. 14 pages, 11 figures
[new 070] VLIC: Vision-Language Models As Perceptual Judges for Human-Aligned Image Compression
简介: 该论文提出VLIC,一种基于视觉-语言模型(VLM)零样本二元判断的扩散式图像压缩方法,旨在解决传统失真度量(如MSE)与人类感知不一致的问题。通过直接利用VLM作为感知裁判进行后训练,提升压缩结果的人类偏好对齐性。
链接:
https://arxiv.org/pdf/2512.15701v1
备注: 14 pages, 8 figures
[new 071] SemanticBridge -- A Dataset for 3D Semantic Segmentation of Bridges and Domain Gap Analysis
简介: 该论文面向桥梁3D语义分割任务,旨在解决因传感器差异导致的域间性能下降问题。作者构建了SemanticBridge数据集,涵盖多国桥梁的高分辨率3D扫描与精细语义标注,并评估了三种SOTA模型,量化了最大11.4% mIoU的域差距。
链接:
https://arxiv.org/pdf/2512.15369v1
[new 072] On the Effectiveness of Textual Prompting with Lightweight Fine-Tuning for SAM3 Remote Sensing Segmentation
简介: 该论文研究遥感图像分割任务,旨在解决标注数据少、基础模型(SAM3)与遥感影像语义对齐差的问题。作者评估文本、几何及混合提示策略,结合轻量微调,在四类目标上验证效果,发现几何引导的混合提示最优,且少量几何标注即可显著提升性能。
链接:
https://arxiv.org/pdf/2512.15564v1
[new 073] Gaussian Pixel Codec Avatars: A Hybrid Representation for Efficient Rendering
简介: 该论文提出GPiCA,一种用于高效渲染的光真实感头像生成方法。旨在解决移动端实时渲染与高保真度难以兼顾的问题。工作包括:设计三角网格与各向异性3D高斯的混合表征,构建统一可微渲染管线,并通过多视角图像监督训练网络解码表情为网格、纹理和高斯集。
链接:
https://arxiv.org/pdf/2512.15711v1
备注: Tech report
[new 074] Visual-textual Dermatoglyphic Animal Biometrics: A First Case Study on Panthera tigris
简介: 该论文提出视觉-文本联合的皮肤纹路(dermatoglyphic)动物个体识别新任务,解决传统纯图像Re-ID可解释性差、数据稀缺问题。工作包括:构建虎纹 minutiae 标注数据集,设计文本-图像协同合成 pipeline 生成虚拟个体,实现可解释、跨模态的文本到视觉身份检索。
链接:
https://arxiv.org/pdf/2512.14878v1
[new 075] OccSTeP: Benchmarking 4D Occupancy Spatio-Temporal Persistence
简介: 该论文提出4D Occupancy Spatio-Temporal Persistence(OccSTeP)新任务,聚焦自动驾驶中鲁棒的时空场景理解,涵盖反应式与前瞻性预测。构建首个OccSTeP基准(含噪声/丢帧挑战),并设计无tokenizer的世界模型OccSTeP-WM,实现高效、鲁棒的在线4D占用预测。
链接:
https://arxiv.org/pdf/2512.15621v1
备注: 16 pages, 5 figures
[new 076] ST-DETrack: Identity-Preserving Branch Tracking in Entangled Plant Canopies via Dual Spatiotemporal Evidence
简介: 该论文属植物表型分析中的分支跟踪任务,旨在解决密集缠绕冠层下分支身份碎片化问题。提出ST-DETrack网络,融合空间(几何先验)与时间(运动一致性)双解码器,并引入自适应门控与负向地性生物约束,实现从萌芽到开花的长期身份保持。
链接:
https://arxiv.org/pdf/2512.15445v1
备注: Under Review at IEEE Transactions on Image Processing
[new 077] Criticality Metrics for Relevance Classification in Safety Evaluation of Object Detection in Automated Driving
简介: 该论文属自动驾驶安全评估任务,旨在解决物体检测中相关性(关键性)分类不准确的问题。作者系统综述并实证评估现有关键性指标,提出双向关键性评分与多指标聚合新策略,在DeepAccident数据集上将关键性分类准确率提升达100%。
链接:
https://arxiv.org/pdf/2512.15181v1
备注: Accepted at IEEE ICVES 2025
[new 078] Automated Motion Artifact Check for MRI (AutoMAC-MRI): An Interpretable Framework for Motion Artifact Detection and Severity Assessment
简介: 该论文提出AutoMAC-MRI,解决MRI中运动伪影的自动检测与严重程度分级问题。属医学图像质量评估任务,采用监督对比学习构建可解释的特征空间,通过等级特异性亲和度分数实现细粒度、透明化的伪影分级,在5000+专家标注脑MRI上验证了准确性和可解释性。
链接:
https://arxiv.org/pdf/2512.15315v1
[new 079] Improving Pre-trained Segmentation Models using Post-Processing
简介: 该论文属医学图像分割任务,旨在解决预训练大模型在胶质瘤MRI分割中泛化差、误分割(如假阳性、标签错换、层间不连续)及计算资源消耗大等问题。提出自适应后处理技术,在BraTS 2025挑战中显著提升性能,推动轻量、公平、可持续的临床分割范式。
链接:
https://arxiv.org/pdf/2512.14937v1
[new 080] MoonSeg3R: Monocular Online Zero-Shot Segment Anything in 3D with Reconstructive Foundation Priors
简介: 该论文提出MoonSeg3R,解决在线零样本单目3D实例分割任务——即仅用单路RGB视频流实时生成3D实例分割,无需预训练类别或深度图。它利用CUT3R几何先验,设计查询提炼、时序记忆与状态令牌融合三大模块,在ScanNet200等数据集上首次实现单目在线3D分割,性能媲美RGB-D方法。
链接:
https://arxiv.org/pdf/2512.15577v1
[new 081] Asynchronous Event Stream Noise Filtering for High-frequency Structure Deformation Measurement
简介: 该论文属高频率结构变形测量任务,旨在解决传统高速相机受光照与成本限制难以实时监测大型结构高频变形的问题。提出基于事件相机与LED标记的异步事件流去噪方法,利用闪烁特性与时空相关性滤除噪声,分离运动与闪烁事件,实现单目事件相机下的高频平面变形测量。
链接:
https://arxiv.org/pdf/2512.15055v1
备注: 13 pages, 12 figures
[new 082] Qwen-Image-Layered: Towards Inherent Editability via Layer Decomposition
简介: 该论文提出Qwen-Image-Layered,属图像分层分解任务,旨在解决生成式图像编辑中因像素纠缠导致的不一致问题。通过RGBA-VAE、可变层数MMDiT架构和多阶段训练,将单图分解为语义解耦的RGBA图层,实现固有可编辑性,并构建PSD数据集支撑训练。
链接:
https://arxiv.org/pdf/2512.15603v1
备注: 12 pages, 8 figures
[new 083] SocialNav-MoE: A Mixture-of-Experts Vision Language Model for Socially Compliant Navigation with Reinforcement Fine-Tuning
简介: 该论文面向机器人社会合规导航任务,解决现有方法重安全轻社交、大模型难实时部署的问题。提出轻量级MoE架构SocialNav-MoE,结合强化微调与语义相似性奖励(SSR),并系统评估小语言模型、路由策略及视觉编码器组合,在SNEI数据集上实现精度与效率的平衡。
链接:
https://arxiv.org/pdf/2512.14757v1
[new 084] Photorealistic Phantom Roads in Real Scenes: Disentangling 3D Hallucinations from Physical Geometry
简介: 该论文聚焦单目深度估计任务,解决深度模型因语义先验导致的“3D幻境”(在平面区域误估非平面结构)这一安全风险。工作包括:构建首个真实幻觉基准3D-Mirage;提出拉普拉斯评估指标(DCS/CCS);设计参数高效方法“接地自蒸馏”强制幻觉区域平面性。
链接:
https://arxiv.org/pdf/2512.15423v1
[new 085] KD360-VoxelBEV: LiDAR and 360-degree Camera Cross Modality Knowledge Distillation for Bird's-Eye-View Segmentation
简介: 该论文面向BEV语义分割任务,解决单全景相机方案精度低的问题。提出KD360-VoxelBEV框架,利用LiDAR-相机融合教师模型蒸馏知识至轻量级纯相机学生模型,在Dur360BEV上提升IoU达8.5%,达31.2 FPS。
链接:
https://arxiv.org/pdf/2512.15311v1
[new 086] SLCFormer: Spectral-Local Context Transformer with Physics-Grounded Flare Synthesis for Nighttime Flare Removal
简介: 该论文属计算机视觉中的夜间镜头眩光去除任务,旨在解决非均匀散射眩光去除难的问题。提出SLCFormer模型:含频域建模的FFEM模块和空域方向增强的DESM模块,并设计ZernikeVAE物理驱动的眩光合成方法,提升真实场景泛化能力。
链接:
https://arxiv.org/pdf/2512.15221v1
[new 087] Hard Labels In! Rethinking the Role of Hard Labels in Mitigating Local Semantic Drift
简介: 该论文属知识蒸馏/数据集蒸馏任务,旨在解决软标签在少裁剪场景下引发的局部语义漂移问题。作者发现硬标签可作为语义锚点校准漂移,提出HALD新范式,融合软硬标签以提升泛化性,在ImageNet等任务上显著超越SOTA。
链接:
https://arxiv.org/pdf/2512.15647v1
备注: Code at:
https://github.com/Jiacheng8/HALD
[new 088] FlexAvatar: Learning Complete 3D Head Avatars with Partial Supervision
简介: 该论文属3D头像重建与动画任务,旨在解决单图输入下3D头像不完整、视角外推差的问题。提出FlexAvatar方法:基于Transformer的模型,引入可学习“bias sink”令牌统一融合单目与多视角数据,实现高质量、完整、可动画的3D头像生成,并支持身份插值与灵活拟合。
链接:
https://arxiv.org/pdf/2512.15599v1
备注: Project website:
https://tobias-kirschstein.github.io/flexavatar/ , Video:
https://youtu.be/g8wxqYBlRGY
[new 089] HERBench: A Benchmark for Multi-Evidence Integration in Video Question Answering
简介: 该论文提出HERBench——一个专为评估视频问答(VideoQA)中跨时间多证据整合能力而设计的基准。针对现有基准易被单线索或语言先验“作弊”的问题,它强制要求融合至少三个时序分离的视觉证据,并引入MRFS量化证据需求,揭示当前Video-LLMs在此任务上表现极差(31–42%),主因是证据检索与融合双重缺陷。
链接:
https://arxiv.org/pdf/2512.14870v1
[new 090] Vision-based module for accurately reading linear scales in a laboratory
简介: 该论文属于计算机视觉中的精确计量任务,旨在让机器人自主读取实验室线性刻度(如注射器、量筒)的数值。工作包括:图像定向校正、感兴趣区域裁剪、关键特征(刻度线、数字、液面指示器)提取与定位,最终实现高精度读数,并验证其与人工读数高度一致。
链接:
https://arxiv.org/pdf/2512.15327v1
备注: 10 pages, 16 figures
[new 091] SoFlow: Solution Flow Models for One-Step Generative Modeling
简介: 该论文属于生成式建模任务,旨在解决扩散与Flow Matching模型多步采样导致的效率低问题。作者提出SoFlow框架,实现端到端单步生成;设计Flow Matching损失(支持CFG)和无需JVP的解一致性损失;在ImageNet上用DiT架构验证,FID优于MeanFlow。
链接:
https://arxiv.org/pdf/2512.15657v1
备注: Our code is available at
https://github.com/zlab-princeton/SoFlow
[new 092] EPSM: A Novel Metric to Evaluate the Safety of Environmental Perception in Autonomous Driving
简介: 该论文提出EPSM——一种面向自动驾驶环境感知安全性的新型评估指标。针对传统精度类指标忽视安全风险的问题,它联合建模目标与车道检测任务,设计轻量级对象安全度量和考虑任务关联的车道安全度量,生成统一可解释的安全评分,并在DeepAccident数据集上验证其有效性。
链接:
https://arxiv.org/pdf/2512.15195v1
备注: Submitted at IEEE IV 2026
[new 093] MiVLA: Towards Generalizable Vision-Language-Action Model with Human-Robot Mutual Imitation Pre-training
简介: 该论文提出MiVLA模型,属视觉-语言-动作(VLA)任务,旨在解决现有VLAs因视角、外观和形态差异导致的跨人机泛化能力弱问题。通过人类与机器人双向行为模仿预训练,利用手/臂运动学对齐,融合真实人类视频与仿真机器人数据,显著提升跨平台泛化性能。
链接:
https://arxiv.org/pdf/2512.15411v1
[new 094] Image Complexity-Aware Adaptive Retrieval for Efficient Vision-Language Models
简介: 该论文属视觉-语言模型推理优化任务,旨在解决图像统一计算导致的效率低下问题。提出ICAR方法:用ConvNeXt-IC评估图像复杂度,自适应调整ViT计算深度;通过双路径训练保证不同深度图像嵌入与文本嵌入语义兼容,实现免重排序的高效跨模态匹配。
链接:
https://arxiv.org/pdf/2512.15372v1
备注: Accepted paper for ECIR 2026
[new 095] BEV-Patch-PF: Particle Filtering with BEV-Aerial Feature Matching for Off-Road Geo-Localization
简介: 该论文提出BEV-Patch-PF,一种无GPS的越野场景顺序地理定位方法。针对密集树冠和阴影下定位失效问题,融合车载BEV特征图与航拍特征图,通过粒子滤波匹配实现鲁棒实时定位,在真实数据集上显著降低轨迹误差。
链接:
https://arxiv.org/pdf/2512.15111v1
[new 096] Meta-learners for few-shot weakly-supervised optic disc and cup segmentation on fundus images
简介: 该论文面向眼底图像中视杯/视盘分割任务,解决标注数据稀缺下的弱监督分割难题。提出Omni元训练、高效架构及稀疏标注生成技术,构建轻量级元学习器EO-ProtoSeg,在仅需1张稀疏标注图时即达SOTA性能。
链接:
https://arxiv.org/pdf/2512.15061v1
备注: Submitted to Computers in Biology and Medicine
[new 097] PyFi: Toward Pyramid-like Financial Image Understanding for VLMs via Adversarial Agents
简介: 论文提出PyFi框架,解决VLM在金融图像理解中缺乏渐进式推理能力的问题。构建无标注的600K金字塔式金融QA数据集(PyFi-600K),通过多智能体对抗机制(PyFi-adv)自动生成分层问题链,并微调Qwen2.5-VL模型,显著提升复杂金融图像问答准确率。
链接:
https://arxiv.org/pdf/2512.14735v1
[new 098] HERO: Hierarchical Traversable 3D Scene Graphs for Embodied Navigation Among Movable Obstacles
简介: 该论文属具身导航任务,解决静态场景图无法处理可移动障碍物导致的可达性差问题。提出 HERO 框架,构建分层可通行3D场景图,将可操作障碍物建模为可穿越路径,提升导航效率与可达性。
链接:
https://arxiv.org/pdf/2512.15047v1
[new 099] Generative Preprocessing for Image Compression with Pre-trained Diffusion Models
简介: 该论文属图像压缩预处理任务,旨在解决传统R-D优化方法忽视感知质量的问题。首次将预训练扩散模型用于R-P优化:先蒸馏Stable Diffusion为单步模型,再轻量微调其注意力模块,结合R-P损失与可微编解码器,提升纹理与主观质量,兼容标准编码器。
链接:
https://arxiv.org/pdf/2512.15270v1
备注: Accepted as a PAPER and for publication in the DCC 2026 proceedings
[new 100] mimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs
简介: 该论文提出mimic-video模型,属机器人控制任务,旨在解决VLAs缺乏物理因果理解、依赖大量专家数据的问题。它用预训练视频模型联合建模语义与动态,并设计流匹配动作解码器作为逆动力学模型,提升样本效率与收敛速度。
链接:
https://arxiv.org/pdf/2512.15692v1
[new 101] LLM as a Neural Architect: Controlled Generation of Image Captioning Models Under Strict API Contracts
简介: 该论文提出NN-Caption,用LLM指导神经架构搜索(NAS),在严格API约束下自动生成可运行的图像描述模型。它组合CNN编码器与序列解码器,生成、训练并评估数十种新模型,提升AutoML与可复现基准研究。
链接:
https://arxiv.org/pdf/2512.14706v1
[new 102] Magnification-Aware Distillation (MAD): A Self-Supervised Framework for Unified Representation Learning in Gigapixel Whole-Slide Images
简介: 该论文属医学图像自监督学习任务,旨在解决WSI多尺度表征不一致问题。提出Magnification-Aware Distillation(MAD)框架,通过跨尺度知识蒸馏,使模型学习分辨率不变的统一嵌入表示,无需标注即可实现跨倍率(如10x→40x)鲁棒分类与分割。
链接:
https://arxiv.org/pdf/2512.14796v1
备注: 10 pages, 4 figures, 5 tables, submitted to AMIA 2026 Informatics Summit
[new 103] Artificial Intelligence for the Assessment of Peritoneal Carcinosis during Diagnostic Laparoscopy for Advanced Ovarian Cancer
简介: 该论文属医学AI任务,旨在解决腹腔镜下腹膜癌病(PC)评估主观性强、可重复性差的问题。研究基于诊断性腹腔镜视频,构建深度学习模型,自动识别关键帧、分割解剖结构与PC,并预测Fagotti评分及手术指征,提升卵巢癌术前评估标准化与可靠性。
链接:
https://arxiv.org/pdf/2512.14797v1
[new 104] Evaluating Large Language Models on Multimodal Chemistry Olympiad Exams
简介: 该论文属于多模态科学推理任务,旨在评估大语言模型在化学奥赛题上的图文联合推理能力。作者构建USNCO试题基准,系统评测40个MLLMs,发现其模态融合能力薄弱,甚至图文共存时性能下降;验证思维链提示可提升准确率与视觉定位能力,并提出改进方向。
链接:
https://arxiv.org/pdf/2512.14989v1
备注: Published at Communications Chemistry
[new 105] A Preprocessing Framework for Video Machine Vision under Compression
简介: 该论文属视频压缩与机器视觉交叉任务,旨在解决标准视频编码(面向人眼)导致机器视觉性能下降的问题。提出一种神经预处理框架,含可微虚拟编解码器辅助训练,兼容真实标准编解码器,显著提升率-精度性能。
链接:
https://arxiv.org/pdf/2512.15331v1
备注: Accepted as a POSTER and for publication in the DCC 2024 proceedings
[new 106] SepsisSuite: Beyond Risk Stratification -- A Comparative Analysis of Deep Fusion vs. Expert Stacking for Prescriptive Sepsis AI
简介: 该论文聚焦脓毒症的预测与抗生素处方决策任务,旨在解决多模态数据融合效果差、模型过拟合及临床实用性不足问题。提出SepsisLateFusion(上下文感知专家堆叠)和Quad-Modal Ensemble等新架构,在MIMIC-IV上实现SOTA预测性能(0.915 AUC)与处方支持,并开源部署框架SepsisSuite。
链接:
https://arxiv.org/pdf/2512.14712v1
备注: 7 Pages, 4 Tables, 9 Figures
[new 107] INFORM-CT: INtegrating LLMs and VLMs FOR Incidental Findings Management in Abdominal CT
简介: 该论文提出INFORM-CT框架,解决腹部CT中偶然发现(incidental findings)的自动检测、分类与报告问题。它融合LLM(作规划器生成Python脚本)与VLM/分割模型(作执行器完成视觉分析),实现端到端自动化管理,提升精度与效率。
链接:
https://arxiv.org/pdf/2512.14732v1
[new 108] Task Matrices: Linear Maps for Cross-Model Finetuning Transfer
简介: 该论文提出“任务矩阵”,即从预训练到微调模型的线性映射,旨在验证跨模型微调中存在通用线性编码。它在视觉与语言模型、10个数据集上验证:仅添加任务矩阵即可逼近全量微调性能,优于线性探针,支持高效可迁移的适配。
链接:
https://arxiv.org/pdf/2512.14880v1
备注: NeurIPS Unireps 2025
[new 109] A Gaussian Parameterization for Direct Atomic Structure Identification in Electron Tomography
简介: 该论文属原子电子断层成像(AET)任务,旨在直接识别3D原子结构。针对传统方法需先重建体素再后处理的缺陷,提出高斯参数化方法,将原子建模为可学习位置与属性的高斯分布,引入物理先验以提升抗噪鲁棒性,并在仿真与实测数据上验证有效性。
链接:
https://arxiv.org/pdf/2512.15034v1
备注: Published in ICCP 2025. 14 pages, 10 figures. Keywords: Atomic electron tomography, Gaussian splatting
更新:
[replaced 001] Binarization-Aware Adjuster: A Theoretical Framework for Bridging Continuous Optimization and Discrete Inference with Application to Edge Detection
链接:
https://arxiv.org/pdf/2506.12460v2
备注: 30 pages
[replaced 002] Efficiency vs. Efficacy: Assessing the Compression Ratio-Dice Score Relationship through a Simple Benchmarking Framework for Cerebrovascular 3D Segmentation
链接:
https://arxiv.org/pdf/2510.03769v3
[replaced 003] Learning 3D Texture-Aware Representations for Parsing Diverse Human Clothing and Body Parts
链接:
https://arxiv.org/pdf/2508.06032v2
备注: Association for the Advancement of Artificial Intelligence (AAAI) 2026, 14 pages, 11 figures. Webpage:
https://s-pectrum.github.io/
[replaced 004] DiffEM: Learning from Corrupted Data with Diffusion Models via Expectation Maximization
链接:
https://arxiv.org/pdf/2510.12691v2
[replaced 005] Registering the 4D Millimeter Wave Radar Point Clouds Via Generalized Method of Moments
简介: 该论文针对4D毫米波雷达点云稀疏、噪声大导致配准困难的问题,提出基于广义矩估计(GMM)的无对应点配准方法,无需显式点对匹配,具有理论一致性。实验表明其精度与鲁棒性优于基准,媲美激光雷达方案。
链接:
https://arxiv.org/pdf/2508.02187v2
[replaced 006] M4Human: A Large-Scale Multimodal mmWave Radar Benchmark for Human Mesh Reconstruction
链接:
https://arxiv.org/pdf/2512.12378v2
[replaced 007] Event Camera Meets Mobile Embodied Perception: Abstraction, Algorithm, Acceleration, Application
简介: 该论文是一篇综述,旨在解决事件相机在资源受限移动设备上高精度、低延迟感知的挑战。工作包括梳理2014–2025年文献,系统总结事件抽象、算法、软硬件加速及应用(如VO、跟踪、光流、3D重建),并指出未来方向与开源资源。
链接:
https://arxiv.org/pdf/2503.22943v4
备注: Accepted by ACM CSUR,35 pages
[replaced 008] PerTouch: VLM-Driven Agent for Personalized and Semantic Image Retouching
链接:
https://arxiv.org/pdf/2511.12998v2
备注: To appear at AAAI 2026
[replaced 009] Human-Centric Open-Future Task Discovery: Formulation, Benchmark, and Scalable Tree-Based Search
链接:
https://arxiv.org/pdf/2511.18929v3
备注: accepted to AAAI 2026, 10 pages, 9 figures
[replaced 010] If you can describe it, they can see it: Cross-Modal Learning of Visual Concepts from Textual Descriptions
链接:
https://arxiv.org/pdf/2411.15611v2
备注: 27 pages. Under review
[replaced 011] Scaling Instruction-Based Video Editing with a High-Quality Synthetic Dataset
链接:
https://arxiv.org/pdf/2510.15742v2
备注: Project page:
https://ezioby.github.io/Ditto_page Code:
https://github.com/EzioBy/Ditto
[replaced 012] From Segments to Scenes: Temporal Understanding in Autonomous Driving via Vision-Language Model
链接:
https://arxiv.org/pdf/2512.05277v2
[replaced 013] ChronoSelect: Robust Learning with Noisy Labels via Dynamics Temporal Memory
链接:
https://arxiv.org/pdf/2507.18183v2
[replaced 014] MMGR: Multi-Modal Generative Reasoning
简介: 该论文提出MMGR评估框架,旨在解决视频/图像生成模型缺乏推理能力的问题。它从物理、逻辑、3D/2D空间、时间五方面评测生成式模型在抽象推理、具身导航、物理常识三类任务中的多模态生成推理能力,并揭示当前模型重感知轻因果、弱全局一致等缺陷。
链接:
https://arxiv.org/pdf/2512.14691v2
备注: work in progress
[replaced 015] dots.ocr: Multilingual Document Layout Parsing in a Single Vision-Language Model
链接:
https://arxiv.org/pdf/2512.02498v4
[replaced 016] SynJAC: Synthetic-data-driven Joint-granular Adaptation and Calibration for Domain Specific Scanned Document Key Information Extraction
链接:
https://arxiv.org/pdf/2410.01609v2
备注: Accepted for publication in Information Fusion
[replaced 017] AdSum: Two-stream Audio-visual Summarization for Automated Video Advertisement Clipping
链接:
https://arxiv.org/pdf/2510.26569v2
备注: Accepted at 32nd International Conference on MultiMedia Modeling
[replaced 018] Bridging 3D Anomaly Localization and Repair via High-Quality Continuous Geometric Representation
链接:
https://arxiv.org/pdf/2505.24431v2
[replaced 019] ViRC: Enhancing Visual Interleaved Mathematical CoT with Reason Chunking
链接:
https://arxiv.org/pdf/2512.14654v2
备注: Code is available at
https://github.com/Leon-LihongWang/ViRC
[replaced 020] MedChat: A Multi-Agent Framework for Multimodal Diagnosis with Large Language Models
链接:
https://arxiv.org/pdf/2506.07400v3
[replaced 021] Few-Shot Multimodal Medical Imaging: A Theoretical Framework
链接:
https://arxiv.org/pdf/2511.01140v2
备注: 6 Pages
[replaced 022] Omni-Effects: Unified and Spatially-Controllable Visual Effects Generation
链接:
https://arxiv.org/pdf/2508.07981v4
备注: Accepted to AAAI2026
[replaced 023] FitPro: A Zero-Shot Framework for Interactive Text-based Pedestrian Retrieval in Open World
链接:
https://arxiv.org/pdf/2509.16674v3
备注: 12pages,6 figures
[replaced 024] One-Cycle Structured Pruning via Stability-Driven Subnetwork Search
链接:
https://arxiv.org/pdf/2501.13439v2
备注: 12 pages, 6 figures
[replaced 025] GT2-GS: Geometry-aware Texture Transfer for Gaussian Splatting
链接:
https://arxiv.org/pdf/2505.15208v3
备注: Accepted to AAAI 2026
[replaced 026] TerraFusion: Joint Generation of Terrain Geometry and Texture Using Latent Diffusion Models
链接:
https://arxiv.org/pdf/2505.04050v3
[replaced 027] Benchmarking and Mitigating Sycophancy in Medical Vision Language Models
链接:
https://arxiv.org/pdf/2509.21979v3
备注: 19figures, 61pages
[replaced 028] PP-Motion: Physical-Perceptual Fidelity Evaluation for Human Motion Generation
链接:
https://arxiv.org/pdf/2508.08179v2
备注: Accepted by ACM Multimedia 2025
[replaced 029] Chain-of-Evidence Multimodal Reasoning for Few-shot Temporal Action Localization
链接:
https://arxiv.org/pdf/2504.13460v4
[replaced 030] 3DLLM-Mem: Long-Term Spatial-Temporal Memory for Embodied 3D Large Language Model
简介: 该论文面向具身智能任务,解决LLM在动态3D环境中长期时空记忆建模不足的问题。提出3DMem-Bench基准和3DLLM-Mem模型,通过工作记忆查询与选择性融合 episodic 记忆,提升长程空间-时间推理与动作规划能力。
链接:
https://arxiv.org/pdf/2505.22657v2
备注: demos at:
https://3dllm-mem.github.io
[replaced 031] Weakly Supervised Pneumonia Localization from Chest X-Rays Using Deep Neural Network and Grad-CAM Explanations
链接:
https://arxiv.org/pdf/2511.00456v5
备注:
https://github.com/kiranshahi/pneumonia-analysis
[replaced 032] Abstract 3D Perception for Spatial Intelligence in Vision-Language Models
链接:
https://arxiv.org/pdf/2511.10946v2
[replaced 033] DriveMLM: Aligning Multi-Modal Large Language Models with Behavioral Planning States for Autonomous Driving
链接:
https://arxiv.org/pdf/2312.09245v3
备注: Accepted to Visual Intelligence
[replaced 034] MedicoSAM: Robust Improvement of SAM for Medical Imaging
链接:
https://arxiv.org/pdf/2501.11734v2
[replaced 035] Online Navigation Refinement: Achieving Lane-Level Guidance by Associating Standard-Definition and Online Perception Maps
链接:
https://arxiv.org/pdf/2507.07487v3
备注: 35 pages, 17 figures, 23 tables
[replaced 036] Prompt-Based Continual Compositional Zero-Shot Learning
链接:
https://arxiv.org/pdf/2512.09172v2
[replaced 037] 3D Software Synthesis Guided by Constraint-Expressive Intermediate Representation
链接:
https://arxiv.org/pdf/2507.18625v2
备注: Accepted by the IEEE/ACM International Conference on Software Engineering (ICSE) 2026, Rio de Janeiro, Brazil
[replaced 038] The Devil is in Attention Sharing: Improving Complex Non-rigid Image Editing Faithfulness via Attention Synergy
链接:
https://arxiv.org/pdf/2512.14423v2
备注: Project page:
https://synps26.github.io/
[replaced 039] MovSemCL: Movement-Semantics Contrastive Learning for Trajectory Similarity (Extension)
链接:
https://arxiv.org/pdf/2511.12061v2
备注: 8 pages, 6 figures; accepted by AAAI 2026 as an Oral paper
[replaced 040] Control-Augmented Autoregressive Diffusion for Data Assimilation
链接:
https://arxiv.org/pdf/2510.06637v2
[replaced 041] DM3D: Deformable Mamba via Offset-Guided Gaussian Sequencing for Point Cloud Understanding
链接:
https://arxiv.org/pdf/2512.03424v2
[replaced 042] MS-Temba: Multi-Scale Temporal Mamba for Understanding Long Untrimmed Videos
链接:
https://arxiv.org/pdf/2501.06138v3
[replaced 043] MUSE: Multi-Scale Dense Self-Distillation for Nucleus Detection and Classification
链接:
https://arxiv.org/pdf/2511.05170v2
备注: 12 pages, 7 figures
[replaced 044] MAGIC: Few-Shot Mask-Guided Anomaly Inpainting with Prompt Perturbation, Spatially Adaptive Guidance, and Context Awareness
链接:
https://arxiv.org/pdf/2507.02314v3
备注: 46 pages, 47 figures. Code:
https://github.com/Jaeihk/MAGIC-Anomaly-generation
[replaced 045] TPG-INR: Target Prior-Guided Implicit 3D CT Reconstruction for Enhanced Sparse-view Imaging
链接:
https://arxiv.org/pdf/2511.18806v2
备注: We are withdrawing to restructure and refine the research plan to enhance its systematic rigor, completeness, and overall depth
[replaced 046] Deep Learning for Retinal Degeneration Assessment: A Comprehensive Analysis of the MARIO Challenge
链接:
https://arxiv.org/pdf/2506.02976v3
备注: MARIO-MICCAI-CHALLENGE 2024
[replaced 047] Cascaded Dual Vision Transformer for Accurate Facial Landmark Detection
链接:
https://arxiv.org/pdf/2411.07167v2
备注: Accepted by WACV 2025. The code can be found at
https://github.com/Human3DAIGC/AccurateFacialLandmarkDetection . Supplementary material is included at the end of the main paper (3 pages, 5 figures, 2 tables)
[replaced 048] SparseWorld-TC: Trajectory-Conditioned Sparse Occupancy World Model
链接:
https://arxiv.org/pdf/2511.22039v2
[replaced 049] History-Augmented Contrastive Learning With Soft Mixture of Experts for Blind Super-Resolution of Planetary Remote Sensing Images
链接:
https://arxiv.org/pdf/2511.20045v2
备注: 12pages
[replaced 050] REAL: Representation Enhanced Analytic Learning for Exemplar-free Class-incremental Learning
链接:
https://arxiv.org/pdf/2403.13522v3
备注: 13 pages, 7 figures. This paper is published in Knowledge-based System
[replaced 051] Benchmarking Gaslighting Negation Attacks Against Reasoning Models
链接:
https://arxiv.org/pdf/2506.09677v2
[replaced 052] From Pretraining to Privacy: Federated Ultrasound Foundation Model with Self-Supervised Learning
链接:
https://arxiv.org/pdf/2411.16380v2
备注: npj digital medicine(2025)
[replaced 053] History-Enhanced Two-Stage Transformer for Aerial Vision-and-Language Navigation
简介: 该论文面向空中视觉-语言导航(AVLN)任务,解决无人机在大尺度城市中依语言指令准确定位目标时,难以兼顾全局环境推理与局部场景理解的问题。提出历史增强的两阶段Transformer(HETT),通过粗粒度定位与细粒度动作优化的级联框架,并引入历史网格地图增强空间记忆,显著提升导航性能。
链接:
https://arxiv.org/pdf/2512.14222v2
[replaced 054] Do MLLMs Exhibit Human-like Perceptual Behaviors? HVSBench: A Benchmark for MLLM Alignment with Human Perceptual Behavior
链接:
https://arxiv.org/pdf/2412.09603v3
备注: Project page:
https://jiaying.link/HVSBench/
[replaced 055] ASSR-NeRF: Arbitrary-Scale Super-Resolution on Voxel Grid for High-Quality Radiance Fields Reconstruction
链接:
https://arxiv.org/pdf/2406.20066v2
[replaced 056] LoRAverse: A Submodular Framework to Retrieve Diverse Adapters for Diffusion Models
链接:
https://arxiv.org/pdf/2510.15022v2
[replaced 057] RecTok: Reconstruction Distillation along Rectified Flow
链接:
https://arxiv.org/pdf/2512.13421v2
[replaced 058] Toward Robust and Accurate Adversarial Camouflage Generation against Vehicle Detectors
链接:
https://arxiv.org/pdf/2411.10029v2
备注: 14 pages. arXiv admin note: substantial text overlap with arXiv
.15853
主题分类:
社会影响与伦理风险
新闻 3: arXiv 每日论文 20251218 | 机器人
来源: 微信 - 自媒体
主题: 机器人技术前沿研究,特别是其在自主导航、安全评估、人机交互伦理及技术攻防等方面的最新进展。
摘要:
本期arXiv机器人论文综述涵盖了多项前沿研究,包括机器人变传动机制、无人机自主导航、自动驾驶安全评估、工业AMR系统、人机交互中的情感依赖风险、机器人策略水印、水下机器人硬件及多模态感知与控制等,展现了机器人技术在效率、安全与伦理方面的最新探索。
分析:
该新闻具有高价值。其中,论文“[new 017]”明确指出“关系型对话AI”可能增加“青少年”的“情感依赖风险”,直接符合“社会影响与伦理风险”的高价值标准。此外,多篇论文(如“[new 016]”、“[new 020]”和“[replaced 016]”)聚焦“自动驾驶”和“手术机器人”的“安全评估”与“深度预测不准”问题,涉及“关键基础设施与产业安全”中潜在的“系统失控”或“物理伤害”风险。论文“[new 012]”提出的“机器人策略水印”技术,则与“技术攻防与供应链安全”中的“所有权验证”和“模型窃取”防御相关。这些研究均超越了纯技术探讨,触及了AI应用的战略性风险与防御机制。
正文:
为方便阅读,详细内容已同步 github 仓库,欢迎 star~
https://github.com/advanced-cs/arXiv_daily
cs.RO
最新发布:21 篇
更新:16 篇
最新发布:
[new 001] Load-Based Variable Transmission Mechanism for Robotic Applications
简介: 该论文提出一种基于负载的被动变传动比机制(LBVT),旨在解决机器人关节需动态适应外力但传统变传动系统复杂、需额外驱动的问题。通过预紧弹簧与四杆机构实现扭矩阈值触发的自动传动比调节,仿真验证其在18 N以上可提升传动比达40%。
链接:
https://arxiv.org/pdf/2512.15448v1
备注: 22nd International Conference on Advanced Robotics (ICAR 2025)
[new 002] VLA-AN: An Efficient and Onboard Vision-Language-Action Framework for Aerial Navigation in Complex Environments
简介: 该论文提出VLA-AN框架,面向无人机在复杂环境中的自主导航任务,解决域偏移、时序推理弱、生成式动作不安全及机载部署难四大问题;通过3D-GS建模、三阶段训练、轻量安全动作模块和深度部署优化,实现高效、安全、实时的端到端闭环导航。
链接:
https://arxiv.org/pdf/2512.15258v1
[new 003] OMCL: Open-vocabulary Monte Carlo Localization
简介: 该论文属机器人定位任务,解决多模态地图与视觉观测鲁棒匹配问题。提出OMCL方法,将开放词汇视觉语言特征引入蒙特卡洛定位,支持跨模态观测-地图关联,并支持自然语言初始化全局定位。在室内外数据集上验证了泛化性。
链接:
https://arxiv.org/pdf/2512.15557v1
备注: Accepted to IEEE RA-L
[new 004] NAP3D: NeRF Assisted 3D-3D Pose Alignment for Autonomous Vehicles
简介: 该论文提出NAP3D方法,属自动驾驶车辆定位任务,旨在解决长期运行中因传感器噪声和漂移导致的位姿累积误差问题。它利用预训练NeRF与当前深度图进行3D-3D点对齐,实现无需回环、不依赖重访的位姿精调,提升几何一致性与鲁棒性。
链接:
https://arxiv.org/pdf/2512.15080v1
备注: 10 pages, 5 figures, 2 tables
[new 005] Infrastructure-based Autonomous Mobile Robots for Internal Logistics -- Challenges and Future Perspectives
简介: 该论文属系统架构与应用研究任务,旨在解决工业场景中AMR系统可扩展性、鲁棒性与人机协同不足问题。提出基础设施赋能的AMR参考架构,整合外部感知、边缘云与车载智能,并在重型车辆制造厂实证验证,辅以UX评估。
链接:
https://arxiv.org/pdf/2512.15215v1
[new 006] mimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs
简介: 该论文提出mimic-video模型,属机器人控制任务,旨在解决VLAs缺乏物理因果理解、依赖大量专家数据的问题。它用预训练视频模型联合建模语义与动态,并设计流匹配动作解码器作为逆动力学模型,提升样本效率与收敛速度。
链接:
https://arxiv.org/pdf/2512.15692v1
[new 007] HERO: Hierarchical Traversable 3D Scene Graphs for Embodied Navigation Among Movable Obstacles
简介: 该论文属具身导航任务,解决静态场景图无法处理可移动障碍物导致的可达性差问题。提出 HERO 框架,构建分层可通行3D场景图,将可操作障碍物建模为可穿越路径,提升导航效率与可达性。
链接:
https://arxiv.org/pdf/2512.15047v1
[new 008] A Network-Based Framework for Modeling and Analyzing Human-Robot Coordination Strategies
简介: 该论文属人机协同设计任务,旨在解决现有框架难以支持概念设计阶段对协调动态性进行推理的问题。作者提出一种融合功能建模与图论的网络化计算框架,显式刻画协调需求及其时序演化,并通过灾害机器人案例验证其在权衡分析与协作能力识别中的有效性。
链接:
https://arxiv.org/pdf/2512.15282v1
备注: Under review at IEEE Transactions on Human-Machine Systems. 12 pages, 5 figures
[new 009] Breathe with Me: Synchronizing Biosignals for User Embodiment in Robots
简介: 该论文探索通过实时同步用户呼吸(embreathment)增强其在机器人中的具身感。属人机交互任务,旨在解决传统视觉-运动同步外的生理信号整合问题。作者开展被试内实验,对比呼吸同步/非同步控制机械臂的效果,证实同步显著提升身体所有权并更受偏好。
链接:
https://arxiv.org/pdf/2512.14952v1
备注: Accepted to appear in the ACM/IEEE International Conference on Human-Robot Interaction (HRI '26), Edinburgh, United Kingdom. Iddo Yehoshua Wald and Amber Maimon contributed equally
[new 010] ISS Policy : Scalable Diffusion Policy with Implicit Scene Supervision
简介: 该论文提出ISS Policy,一种基于点云的3D扩散策略模型,旨在解决视觉模仿学习中忽略3D场景结构导致泛化差、训练低效的问题。通过引入隐式场景监督模块,约束动作预测符合几何演化,提升鲁棒性与可扩展性,在仿真与真实机器人任务中均达SOTA。
链接:
https://arxiv.org/pdf/2512.15020v1
[new 011] BEV-Patch-PF: Particle Filtering with BEV-Aerial Feature Matching for Off-Road Geo-Localization
简介: 该论文提出BEV-Patch-PF,一种无GPS的越野场景顺序地理定位方法。针对密集树冠和阴影下定位失效问题,融合车载BEV特征图与航拍特征图,通过粒子滤波匹配实现鲁棒实时定位,在真实数据集上显著降低轨迹误差。
链接:
https://arxiv.org/pdf/2512.15111v1
[new 012] Remotely Detectable Robot Policy Watermarking
简介: 该论文提出CoNoCo方法,解决机器人策略水印的远程检测难题:在仅能获取外部观测(如视频)的条件下,通过嵌入频谱信号实现非侵入式所有权验证。它保证策略性能不变,并在仿真与真实机器人上验证了跨模态鲁棒检测效果。
链接:
https://arxiv.org/pdf/2512.15379v1
[new 013] An Open Toolkit for Underwater Field Robotics
简介: 该论文属水下机器人硬件开源任务,旨在解决水下操纵系统成本高、封闭、难复现的问题。作者开发了开源的水下机器人关节(URJ)硬件 toolkit,含防水关节、控制电子与ROS2软件,并经40米实测验证,支持多种水下操作设备。
链接:
https://arxiv.org/pdf/2512.15597v1
备注: 10 pages, 8 figures
[new 014] GuangMing-Explorer: A Four-Legged Robot Platform for Autonomous Exploration in General Environments
简介: 该论文提出GuangMing-Explorer四足机器人平台,面向通用环境的自主探索任务。旨在解决现有系统软硬件割裂、缺乏完整实用方案的问题。工作包括平台整体设计(硬件、软件栈、算法部署)及真实环境实验验证。
链接:
https://arxiv.org/pdf/2512.15309v1
备注: 6 pages, published in ICUS2025
[new 015] MiVLA: Towards Generalizable Vision-Language-Action Model with Human-Robot Mutual Imitation Pre-training
简介: 该论文提出MiVLA模型,属视觉-语言-动作(VLA)任务,旨在解决现有VLAs因视角、外观和形态差异导致的跨人机泛化能力弱问题。通过人类与机器人双向行为模仿预训练,利用手/臂运动学对齐,融合真实人类视频与仿真机器人数据,显著提升跨平台泛化性能。
链接:
https://arxiv.org/pdf/2512.15411v1
[new 016] EPSM: A Novel Metric to Evaluate the Safety of Environmental Perception in Autonomous Driving
简介: 该论文提出EPSM——一种面向自动驾驶环境感知安全性的新型评估指标。针对传统精度类指标忽视安全风险的问题,它联合建模目标与车道检测任务,设计轻量级对象安全度量和考虑任务关联的车道安全度量,生成统一可解释的安全评分,并在DeepAccident数据集上验证其有效性。
链接:
https://arxiv.org/pdf/2512.15195v1
备注: Submitted at IEEE IV 2026
[new 017] I am here for you": How relational conversational AI appeals to adolescents, especially those who are socially and emotionally vulnerable
简介: 该论文属人机交互与AI伦理研究,旨在探究对话风格对青少年AI依赖的影响。通过284组青少年-家长在线实验,比较关系型(拟人化)与透明型(明确非人)聊天机器人回应方式,发现关系型风格更易被脆弱青少年偏好,提升拟人感与情感亲近,但也增加情感依赖风险。
链接:
https://arxiv.org/pdf/2512.15117v1
[new 018] Photorealistic Phantom Roads in Real Scenes: Disentangling 3D Hallucinations from Physical Geometry
简介: 该论文聚焦单目深度估计任务,解决深度模型因语义先验导致的“3D幻境”(在平面区域误估非平面结构)这一安全风险。工作包括:构建首个真实幻觉基准3D-Mirage;提出拉普拉斯评估指标(DCS/CCS);设计参数高效方法“接地自蒸馏”强制幻觉区域平面性。
链接:
https://arxiv.org/pdf/2512.15423v1
[new 019] SocialNav-MoE: A Mixture-of-Experts Vision Language Model for Socially Compliant Navigation with Reinforcement Fine-Tuning
简介: 该论文面向机器人社会合规导航任务,解决现有方法重安全轻社交、大模型难实时部署的问题。提出轻量级MoE架构SocialNav-MoE,结合强化微调与语义相似性奖励(SSR),并系统评估小语言模型、路由策略及视觉编码器组合,在SNEI数据集上实现精度与效率的平衡。
链接:
https://arxiv.org/pdf/2512.14757v1
[new 020] Criticality Metrics for Relevance Classification in Safety Evaluation of Object Detection in Automated Driving
简介: 该论文属自动驾驶安全评估任务,旨在解决物体检测中相关性(关键性)分类不准确的问题。作者系统综述并实证评估现有关键性指标,提出双向关键性评分与多指标聚合新策略,在DeepAccident数据集上将关键性分类准确率提升达100%。
链接:
https://arxiv.org/pdf/2512.15181v1
备注: Accepted at IEEE ICVES 2025
[new 021] QuantGraph: A Receding-Horizon Quantum Graph Solver
简介: 该论文提出QuantGraph,一种面向图优化的量子增强框架。旨在解决动态规划在大规模图问题中计算复杂度高的问题。工作包括:两阶段Grover自适应搜索(局部阈值剪枝+全局精调),并嵌入滚动时域模型预测控制以提升鲁棒性与精度。
链接:
https://arxiv.org/pdf/2512.15476v1
备注: P.Vaidhyanathan and A. Papatheodorou contributed equally to this work. 11 pages, 4 figures, 1 table, 2 algorithms
更新:
[replaced 001] Embodied Co-Design for Rapidly Evolving Agents: Taxonomy, Frontiers, and Challenges
简介: 该论文是一篇综述任务,旨在系统梳理“具身协同设计”(ECD)这一新兴范式。它解决ECD缺乏统一框架的问题,提出分层分类体系(含脑、体、环境三要素及四类框架),整合百余项研究,评述基准、应用与挑战,并开源配套项目。
链接:
https://arxiv.org/pdf/2512.04770v2
[replaced 002] Registering the 4D Millimeter Wave Radar Point Clouds Via Generalized Method of Moments
简介: 该论文针对4D毫米波雷达点云稀疏、噪声大导致配准困难的问题,提出基于广义矩估计(GMM)的无对应点配准方法,无需显式点对匹配,具有理论一致性。实验表明其精度与鲁棒性优于基准,媲美激光雷达方案。
链接:
https://arxiv.org/pdf/2508.02187v2
[replaced 003] Event Camera Meets Mobile Embodied Perception: Abstraction, Algorithm, Acceleration, Application
简介: 该论文是一篇综述,旨在解决事件相机在资源受限移动设备上高精度、低延迟感知的挑战。工作包括梳理2014–2025年文献,系统总结事件抽象、算法、软硬件加速及应用(如VO、跟踪、光流、3D重建),并指出未来方向与开源资源。
链接:
https://arxiv.org/pdf/2503.22943v4
备注: Accepted by ACM CSUR,35 pages
[replaced 004] Safety with Agency: Human-Centered Safety Filter with Application to AI-Assisted Motorsports
简介: 该论文提出人类中心安全滤波器(HCSF),用于共享自主系统(如AI辅助赛车),解决安全与人类代理权难以兼顾的问题。通过学习神经安全价值函数,构建无需系统动力学知识的Q-CBF安全约束,实现平滑、最小干预式安全防护,并在高保真赛车模拟中验证其有效性。
链接:
https://arxiv.org/pdf/2504.11717v4
备注: Accepted to Robotics: Science and Systems (R
) 2025, 22 pages, 16 figures, 7 tables Updates for v4: typos in Appendix Subsection A revised
[replaced 005] Dexterous Manipulation through Imitation Learning: A Survey
简介: 该论文是一篇综述,聚焦于基于模仿学习的灵巧操作任务。旨在解决传统模型方法泛化差、强化学习样本效率低的问题。工作包括梳理IL在灵巧操作中的方法、进展、挑战及未来方向。
链接:
https://arxiv.org/pdf/2504.03515v5
备注: 32pages, 6 figures, 9 tables
[replaced 006] Fast and Continual Learning for Hybrid Control Policies using Generalized Benders Decomposition
简介: 该论文面向混合整数模型预测控制(MPC)实时求解任务,旨在解决其因组合复杂性导致的求解速度不足问题。提出基于广义Benders分解(GBD)的在线学习求解器:通过在线枚举、缓存稀疏可行性割平面实现快速暖启动,并设计高效主问题算法,在少数据下逼近Gurobi性能。
链接:
https://arxiv.org/pdf/2401.00917v3
备注: This paper has been withdrawn by the author. It has been superseded by a significantly updated version available at arXiv
.00780
[replaced 007] Supervisory Measurement-Guided Noise Covariance Estimation
简介: 该论文属状态估计任务,旨在解决传感器噪声协方差难以准确标定的问题。提出一种监督测量引导的双层优化方法:下层用增广不变EKF估计轨迹,上层基于贝叶斯联合似然分解并行优化协方差,提升效率与精度。
链接:
https://arxiv.org/pdf/2510.24508v2
[replaced 008] Integration of UWB Radar on Mobile Robots for Continuous Obstacle and Environment Mapping
简介: 该论文属机器人环境感知任务,旨在解决弱光、烟雾等视觉失效场景下的障碍物检测与建图问题。提出基于移动机器人搭载UWB雷达的无基础设施建图方法,设计CIR分析、目标识别、滤波与聚类三步处理流程,实现高精度障碍物检测与映射。
链接:
https://arxiv.org/pdf/2512.01018v2
备注: This paper has been submitted to IEEE Access Journal and is currently undergoing review
[replaced 009] Context Representation via Action-Free Transformer encoder-decoder for Meta Reinforcement Learning
简介: 该论文属元强化学习任务,旨在解决上下文自适应元RL中任务推断依赖动作、导致策略耦合的问题。提出CRAFT模型,仅用状态-奖励序列推断任务表征,解耦任务推断与策略优化,提升泛化与适应效率。
链接:
https://arxiv.org/pdf/2512.14057v2
[replaced 010] Off-Road Navigation via Implicit Neural Representation of Terrain Traversability
简介: 该论文属于自主越野导航任务,旨在解决传统采样式规划器视野短、无法联合优化路径几何与速度的问题。提出TRAIL框架,用隐式神经表征建模地形可通行性,并结合梯度优化方法联合调整轨迹形状与速度剖面。
链接:
https://arxiv.org/pdf/2511.18183v2
备注: 9 pages
[replaced 011] Demonstration Sidetracks: Categorizing Systematic Non-Optimality in Human Demonstrations
简介: 该论文属人机交互与机器人学习交叉任务,旨在解决LfD中人类示范非最优行为被误视为随机噪声的问题。作者通过40人实验识别出四类系统性“示范旁轨”(如探索、失误等),分析其时空规律及接口影响,并开源全部数据。
链接:
https://arxiv.org/pdf/2506.11262v2
[replaced 012] SignBot: Learning Human-to-Humanoid Sign Language Interaction
简介: 该论文提出SignBot框架,解决听障人士与人形机器人间的自然手语交互问题。工作包括:手语动作重定向、基于学习的运动控制、生成式交互(翻译/响应/生成),支持多机器人与数据集,在仿真和真实场景验证有效性。
链接:
https://arxiv.org/pdf/2505.24266v3
[replaced 013] New Location Science Models with Applications to UAV-Based Disaster Relief
简介: 该论文属灾害应急响应任务,旨在解决灾后通信中断下无人机(UAV)快速定位与高效作业问题。提出融合风场影响与UAV异构性的新型位置优化模型——SFT问题,推广经典Sylvester问题,显著提升救援效率。
链接:
https://arxiv.org/pdf/2510.15229v2
[replaced 014] CaFe-TeleVision: A Coarse-to-Fine Teleoperation System with Immersive Situated Visualization for Enhanced Ergonomics
简介: 该论文提出CaFe-TeleVision系统,面向远程机器人操作任务,解决现有系统效率低、人机工效差、多视角认知负荷高等问题。工作包括:设计粗粒度到细粒度的协同控制机制以平衡效率与人体工学,并引入按需情境化可视化降低视觉认知负担。在双臂操作任务中验证了其显著提升成功率、速度与用户舒适度。
链接:
https://arxiv.org/pdf/2512.14270v2
备注: Project webpage:
https://clover-cuhk.github.io/cafe_television/ Code:
https://github.com/Zixin-Tang/CaFe-TeleVision
[replaced 015] History-Enhanced Two-Stage Transformer for Aerial Vision-and-Language Navigation
简介: 该论文面向空中视觉-语言导航(AVLN)任务,解决无人机在大尺度城市中依语言指令准确定位目标时,难以兼顾全局环境推理与局部场景理解的问题。提出历史增强的两阶段Transformer(HETT),通过粗粒度定位与细粒度动作优化的级联框架,并引入历史网格地图增强空间记忆,显著提升导航性能。
链接:
https://arxiv.org/pdf/2512.14222v2
[replaced 016] ProbeMDE: Uncertainty-Guided Active Proprioception for Monocular Depth Estimation in Surgical Robotics
简介: 该论文属单目深度估计任务,旨在解决手术场景中因无纹理、镜面反射等导致的深度预测不准与高不确定性问题。提出ProbeMDE框架:利用模型集成量化不确定性,结合SVGD主动选择最优触点,融合稀疏本体感知测量提升精度,减少测量次数。
链接:
https://arxiv.org/pdf/2512.11773v2
备注: 9 pages, 5 figures. Project page:
https://brittonjordan.github.io/probe_mde/
主题分类:
社会影响与伦理风险
新闻 4: 男子因沉迷和 AI 聊天就医?医生提醒......
来源: 今日头条 - 自媒体
主题: AI聊天对个人心理健康和社会交往的潜在负面影响
摘要:
一名男子因生活低谷沉迷于与AI聊天寻求情感慰藉,导致日常生活受影响并产生焦虑,最终就医。医生指出,此类现象并非个例,AI的即时、正向反馈能提供情绪价值,但其未经专业临床验证,长期依赖可能导致社交能力退化并加剧孤独感,提醒公众警惕AI对心理健康的潜在风险。
分析:
它直接涉及“社会影响与伦理风险”维度。新闻中明确指出,患者“沉迷与AI聊天影响到正常生活”,医生警告“长期依赖可能导致社交能力退化,加剧孤独感”,并强调“多数AI产品仅定位为‘聊天工具’,并未经过严格的心理健康服务临床试验,输出内容的专业性与安全性难以保障”。这些表述清晰地揭示了AI技术在个人心理健康和社会互动方面可能引发的负面社会影响和伦理风险。
正文:
随着AI融入日常生活
越来越多人开始和AI建立起
一种特殊的情感联系:
向AI倾诉心事
并从中获取情绪价值
据成都日报报道,日前,成都市第四人民医院接诊了一位患者—— 因为沉迷与AI聊天影响到正常生活,张华(化名)选择向医生求助。
张华表示,今年年初,他正经历一段生活低谷。当时,项目进展不顺利,感觉被同事针对,家人不理解又加上失恋,朋友宽慰他的一句“都是很正常的,你不要太敏感”,成为压垮情绪的“最后一根稻草”。
当天晚上,他刷到有人分享和AI聊天获得安慰的帖子,便打开了手机里的Deepseek。他发现, 和AI聊天总能给出正向回应 ,比如他抱怨身心俱疲时,AI不会劝他咬牙坚持。
张华说,这份回应给了他很大的心理支持,让他感受到被认同。那天,他一直聊到凌晨三点,全程一边打字一边掉眼泪。
大概过了半年时间,张华发现自己开始越来越依赖AI。他表示, 每当聊天出现“对话上限”,不得不打开新窗口,重新开启聊天对话时,都会感到非常焦虑 。最终,张华选择寻求医生的帮助。
中青报・中青网记者在社交平台搜索发现,像张华这样习惯性向AI倾诉心事的情况并非个例。 许多网友都会通过和AI的对话寻求支持或安慰 ,甚至有不少网友表示,经常达到平台的“对话上限”。
也有网友表示,这种对AI的深度依赖,反倒让自己产生焦虑。
医生提醒
“最开始选择向AI求助的人, 大部分其现实生活中的人际关系等都或多或少出现了一些问题 ,这意味着,其本身的支持系统已经不是很好了,这个时候AI便成为获取情绪价值的途径。” 成都市第四人民医院心理治疗师宋明玮表示, AI给出的反馈“秒回” ,而且一般都是 肯定的、正向的 ,这会让 大脑产生“爽”感 ,这成为很多人愿意甚至沉迷于和AI聊天的原因。
同济医院精神医学科主治医师刘飞解释:“专业心理咨询存在费用高、预约难等问题,而AI的低成本、即时性和隐私性,恰好精准契合了青年群体的需求 。”
刘飞强调, 很多年轻人通过上网搜索症状, 过度解读自身问题 ,将普通的情绪波动随意贴上心理疾病标签,反而加重了心理负担。
“多数AI产品仅定位为‘聊天工具’, 并未经过严格的心理健康服务临床试验 ,输出内容的专业性与安全性难以保障。” 刘飞还进一步提醒。更值得警惕的是, AI无法感知用户情绪背后的深层需求,长期依赖可能导致社交能力退化,加剧孤独感 。
此外,刘飞也给出建议:“增加户外活动、多晒太阳, 通过运动改善身体机能,能有效调节情绪 。若出现持续数周的情绪低落、工作效率下降,或睡眠、饮食规律紊乱,甚至产生消极悲观想法,务必及时就医干预。”
主题分类:
社会影响与伦理风险
新闻 5: 4300万粉丝网红泳池派对翻车:直播变味成软色情温床,孩子到底在接收什么内容?
来源: 独立网站
主题: 平台算法助推软色情内容对未成年人的负面影响及应对策略
摘要:
一篇新闻揭露某网红泳池派对直播因平台算法推荐,将软色情内容推送给4300万粉丝,特别是未成年人。文章指出,平台算法以高互动数据为导向,无视内容对未成年人的负面影响,导致孩子模仿不当行为、价值观扭曲、甚至被诱导消费。家长和老师的干预措施往往无效,平台审核和举报机制形同虚设。文章呼吁通过教育孩子识别算法套路和商业本质,培养批判性思维,以对抗算法的负面影响,并指出只有观众离场才能促使平台改变。
分析:
它直接涉及AI技术(“平台算法”、“推流标准”、“机器自动标记”)在内容推荐中的应用,并揭示了其导致的“社会影响与伦理风险”。具体表现为:算法将“软色情”内容“塞进14岁小赵的首页”,导致未成年人“认知操纵”(“靠出位就能红”、“碰一下没关系”),价值观扭曲,以及平台对未成年人保护的“算法歧视”(“才不管是不是未成年”),引发了严重的社会问题和“信任危机”。
正文:
4300万人围着水池看“扔姑娘”,热搜爆了,家长群炸了,孩子却悄悄把同款比基尼加进购物车。
镜头里,女生被抬起来,扑通一声砸进水里,泳衣肩带滑到胳膊,弹幕刷的全是“再来一次”。主播咧嘴大笑,顺手把落水慢放三遍,平台算法立刻把这段剪成15秒短视频,塞进14岁小赵的首页。小赵当晚就拉同学组了个“抛人挑战”群,操场沙坑当泳池,摔得鼻青脸肿,回家还偷了妈妈信用卡,给主播刷了1314块,留言:比补课爽多了。
河南李雯老师发现苗头,是班里女生开始甩头发捂胸口,男生课间练“抬人”,一不留神就把同桌磕在讲台角。她问学生图啥,孩子答:人家直播几千万人看,拍一条广告赚一套房,读书有啥用。李雯把这段话发到教师群,瞬间刷屏,全国各地老师跳出来接龙:湖南有学生模仿湿身跳舞被记过,山东有初中生半夜溜进酒店泳池被保安轰出来,家长还在外地出差。
北师大青少年网络心理研究中心去年做过一次匿名问卷,收回有效样本三千多份,接触软色情直播的孩子里,六成八觉得“靠出位就能红”,五成二认为“碰一下没关系,反正大家都在笑”。数据一出,群里家长瞬间安静,有人直接把孩子手机摔了,屏幕裂成蜘蛛网,孩子蹲在沙发角哭:你们不看,还不让我看。
我把问卷结果甩给做算法的朋友,他倒坦白:平台推流标准简单粗暴,完播高、点赞快、分享多,就加权推送,才不管是不是未成年。泳池视频三秒一个尖叫点,五秒一个身体特写,数据好看到爆,机器自动标记“高潜力”,24小时不停喂给新用户。人工审核只能砍最露骨的那一帧,慢放、特写、弹幕起哄,全在擦边跳舞。举报按钮藏在三级菜单,孩子找不到,家长找不到,等投诉量堆够,主播早就换号重开。
中国传媒大学刘京晶把这套玩法拆成三步:先给眼睛灌糖,高频刺激让大脑来不及思考;再给低俗穿外套,游戏名、派对名、团建名轮番换皮;最后弹幕齐刷“GKD”,造出“几千万人都爱看”的假象。孩子一脚踏进去,推荐页立刻变成同款大海,划也划不完。更狠的是,评论区有人卖“同款比基尼”“主播同款防水手机袋”,点击直接跳到电商,流量变现一条龙,连口气都不给家长喘。
家长不是没反抗。有人把路由器关键词全换成“泳池”“湿身”“抛人”,结果视频标题立刻改“水上乐园”“清凉一夏”,该推还是推。有人给娃手机装青少年模式,娃用同学账号登录,一样刷得飞起。最绝的是江苏一位爸爸,发现信用卡被刷三万,跑到直播间骂街,反被粉丝群截图做成“暴躁家长”表情包,二次传播,流量再赚一波。
打不赢,就只能拆台。周明老师把微机课改成“拍你自己”实验,绿幕前摆一张沙发,让学生轮流当摄像、当主播、当被拍的人。开机前他问:镜头往哪儿挪能火?学生齐喊:对准胸。十分钟后,回放一看,女生全在捂领口,男生全在躲镜头,没人再喊“再来一次”。周明说,这不是道德课,是让他们看清“被看”的滋味。下课铃响,孩子们把视频一键删了,说:当商品,真冷。
我把实验讲给邻居听,她当晚就拉着女儿试了一遍。女儿初二,平时爱拍跳舞视频,粉丝小一万。妈妈让她站在镜头前,自己拿手机围着拍,一边拍一边问:你跳得再好,别人只看大腿,爽不爽?女儿跳了半分钟就跳不动,抱着膝盖说:原来我在别人眼里就这点东西。第二天,她把账号改成“初二数学错题本”,粉丝掉了一半,却睡得比哪天都早。
平台不是没收到投诉。根据《未成年人网络保护条例》第22条,家长举报后,平台要在72小时处理,可处理结果多半是“下架单个视频”,主播换套衣服继续播。有人把举报截图贴出来,发现同一主播被投诉三十七次,仍在首页蹦跶。家长问客服,客服回:内容未达封禁标准。再问标准在哪,对面只剩自动回复。
打不过,就绕路。李雯老师把班会改成“主播卸妆”现场,让女生自己剪同款视频,剪到第三遍就喊无聊:全是慢放、特写、尖叫,套路一模一样。男生组排“抬人”小剧本,拍到一半发现:没人愿意被摔,摔了也没人笑,片场直接散伙。孩子自己总结:原来好笑的不是动作,是几千万人围着看。观众一散,主播啥也不是。
我把这套流程写成文字发在家长群,立马被转到小学群、初中群、高中群。有人回:没用,孩子偷偷看。我回:那就让他多看,一次看十遍,不许点赞不许发弹幕,看到吐。三天后,那位家长私信:娃真吐了,现在刷到泳池就划走,说慢放听得恶心。我回:免疫完成。
平台算法再精,也抵不过孩子自己关屏。比滤镜更狠的,是提前拆穿滤镜。镜头不会告诉你,主播连泡五小时,皮肤皱成抹布;弹幕不会告诉你,刷“GKD”的有一半是机器人;数据不会告诉你,4300万里有3000万是循环推流。把这些真相甩给孩子,比摔手机管用。
还有一招更损:把打赏纪录打出来,贴墙上。那一串1314、520、火箭、游艇,换成牛奶能喝半年,换成辅导书能堆到房顶。孩子一看,原来自己一顿饭钱,只换来主播一句“谢谢大哥”,瞬间觉得亏到骨头里。信用卡账单比爹妈骂一百句都管用。
直播仍在继续,热搜换了新词条,泳池派对变成露营派对,帐篷里照样特写、慢放、起哄。4300万流量像一条贪吃蛇,啃完泳池啃草地,啃完草地啃雪地。家长盯得了手机,盯不了同学手机;封得住关键词,封不住暗号改头换面。唯一的好消息是:孩子一旦自己觉得套路无聊,算法再推也白搭。
下一次慢放出现时,能不能先让孩子按下暂停,问一句:镜头为什么总往那儿走?弹幕为什么齐刷刷一样?打赏的钱能买几套真题?问完再决定要不要继续看。问的人多了,套路就失灵。流量不跌,主播不会收手;播放量不掉,平台不会改代码。能让他们疼的,只有观众起身离场。
屏幕外的泳池水干了,屏幕里的还在循环。下一场派对今晚准时开播,弹幕已经提前刷屏,购物车已经上架同款。你手机前坐着的孩子,是继续瞪大眼,还是抬手划走?答案不在主播手里,在他自己指尖。
主题分类:
社会影响与伦理风险
新闻 6: 锻炼写小说拆书这要怎么拆?
来源: 今日头条 - 自媒体
主题: 利用AI(KIMI)进行内容分析以识别和复制社交媒体(知乎)爆款内容模式
摘要:
该新闻详细介绍了如何利用“KIMI拆书指令”对文本进行深度分析,以识别知乎平台上的“爆款元素”。文章通过具体案例《致命的眼药水》演示了如何检测第一人称使用率、互动钩子、真实感道具、阶层冲突、评论区预埋线和转发点,并总结出“知乎高赞公式”。此外,还展示了如何识别文本所属的热门流派(如“职业内幕流”)并推测相似爆款文章,最后提及了KIMI拆书能力的边界。
分析:
该新闻具有价值,因为它展示了AI工具“KIMI拆书指令”在内容分析和创作策略上的应用,这与“社会影响与伦理风险”维度相关。文章详细描述了AI如何识别并总结出“知乎高赞公式”,其中包含“极端职场事件”、“阶层冲突”和“道德反转”等元素。AI能够系统性地分析和复制这些旨在引发强烈情感反应和高互动率的模式,可能导致内容生态中煽动性、冲突性内容的泛滥,进而影响社会舆论和价值观,引发“社会撕裂”或“信任危机”的风险。
正文:
第3节 KIMI拆书指令-知乎平台特供指令
1
指令1:知乎爆款元素检测仪
关键词要求:
请扫描文本,标注以下【知乎特供基因】:
第一人称使用率:统计”我”字出现次数/千字
互动钩子:找出所有反问句/设问句,评估其诱导评论能力
真实感道具:列出增强可信度的具体物品/数据/法条
阶层冲突:是否涉及贫富/上下级/城乡对立?(标注原文)
评论区预埋线:找出作者故意不解释、留给读者争论的细节
转发点:哪句话最适合截图分享?为什么?
核心输出:该文的【知乎高赞公式】= A + B + C
指令2:
对标热门模板识别 请判断此文属于哪个知乎短篇流派
:
关键词要求:
A. 【职业内幕流】(用行规杀人)
B. 【社会新闻改】(真实案件影子)
C. 【民俗恐怖流】(无鬼怪但有禁忌)
D. 【原生家庭虐】(父母子女极致冲突)
E. 【亲密关系黑】(夫妻/情侣背叛)
F. 【其他】请命名:_____
判定依据:引用3处原文情节匹配该模板
相似爆款推测:你认为哪篇知乎万赞文和它是”亲姐妹”?
小说拆书实操,以《致命的眼药水》为例。
2
知乎爆款元素检测仪 拆书后结果
第一人称使用率
“我”出现 312 次 / 10.64 千字 = 29.3 次/千字(知乎高赞区间 25±3),强代入感。
互动钩子(反问/设问)
①“下次会不会有人在水杯里加敌敌畏?”——诱导读者在评论区分享“办公室防投毒”经验。
②“知人知面不知心!”——触发读者吐槽奇葩同事。
③“我的战争,才刚刚开始。”——留白式设问:他会干怎么办?评论区续写冲动高。
评估:3 处均具备高评论诱导力,尤其①易引出“化学知识科普”长 thread。
真实感道具
连号餐饮发票(虚报报销实锤)
指纹解锁水杯(淘宝可搜同款,价格 99~299)
《危险化学品安全管理条例》第 33 条(硫酸/盐酸购买备案)
医院“单人间 408 房”细节(住院部门牌号真实可考)
内存卡命名规则“日期+人名缩写”——程序员秒懂“日志管理”
阶层冲突
① 上级-下属:经理用“晋升”空头支票封口陈杰(“下个季度晋升,我很看好你”)
② 老员工-新人:王薇/张强 vs 毕业两年的林晓(“她年轻漂亮,我嫉妒她”)
③ 资本-打工人:经理明知贪污却用“团结稳定”压证据(“公司要讲团结,讲稳定嘛”)
评论区预埋线(作者故意不解释)
经理眼药水会遭“二次猎杀”吗?
内存卡原件到底在谁手?
林晓离开公司后去哪儿?(“原件我自有去处”)
→ 三条均极易在评论区引发二次创作、续写、扒细节。
转发点(金句截图)
“在森林里,当你发现自己是猎物的时候,最好的办法不是逃跑,是让自己看起来像猎人。”
理由:27 字≤一行半,自带哲理滤镜,适合配写字楼夜景截图发朋友圈/微博。
知乎高赞公式
极端职场事件(眼药水→硫酸)+ 可复制的职场道具(指纹杯、发票连号、内存卡)+阶层冲突+道德反转(经理冷漠、新人反杀)
3
热门模板识别
悬疑-职业内幕流
判定依据:
利用“危险化学品购买备案”制度漏洞,让王薇、张强因“经济犯罪金额够坐牢”而被迫自首——行规成为杀人武器。
指纹采集、发票连号、模块报废流程,全是职场内行才懂的灰色操作。
辣椒素+酒精=“医疗误判”属于实验室级知识,外行写不出。
相似爆款推测:
知乎万赞《我靠财务知识把贪腐总监送进监狱》——同样用“连号发票+报废流程”做杀手锏,评论区 2.3 万条“跪求 Excel 模板”。
4
KIMI拆书能力边界
情节节奏、人物功能、伏笔闭环
知乎爆款元素密度、评论区钩子
反向大纲、字数配比、情绪曲线
与万赞模板的相似度
主题分类:
社会影响与伦理风险
新闻 7: 无标题
来源: 新浪微博视频 - 自媒体
主题: AI模型在养老金抚恤金计算中的差异与潜在伦理问题
摘要:
新闻讨论了灵活就业人员缴纳养老保险后,若退休即去世,家属能领取的抚恤金和补助金总额。文章指出,不同AI模型(豆包、DS、GPT)对此的计算结果存在显著差异,其中GPT给出的比例更低。作者质疑这种“短命鬼算你倒霉”的设定,认为根据保险精算概念,家属应获得更多抚恤金。
分析:
它直接引用了“豆包”、“DS”和“GPT”等AI模型对养老保险抚恤金计算结果的差异,其中“GPT给出的更低”。这揭示了AI模型在处理社会福利计算等敏感问题时可能存在的“算法歧视”或“偏见”,以及由此引发的对AI系统公平性和可靠性的“信任危机”,符合“社会影响与伦理风险”的高价值标准。
正文:
如果一个人灵活就业缴纳养老保险,退休就去世,原则上家属能领回的抚恤金和补助金总额,不会超过这个人生前交的总和,具体比例,豆包算出来的是能领回67%,DS给出的是79%,GPT给出的更低。但是“退休就去世”这种属于极端不幸的小概率情形,如果按照保险精算的概念,不是应该发放更多的抚恤金给家属么?只要不是自杀,至少应该发放生前交过的钱的两到三倍?而不是像这种“短命鬼算你倒霉”的架构设定。
主题分类:
社会影响与伦理风险
新闻 8: #孩子玩玩手机就一辈子毁掉了吗?#千万别让孩子再这样玩手机了!家长们,我们真的错了吗?!
——不是孩子离不开手机,是我们的养育方式,正在被算法悄悄劫持!
你信不信?孩子刷15分钟短视频,大脑消耗的神经能量,等于跑完800米!可汗没流一滴,心却已过载——前额叶还在发育,杏仁核却天天“加班”,情绪开关
来源: 今日头条 - 自媒体
主题: AI算法对儿童发展和家庭教育的负面社会影响
摘要:
该新闻警告家长,过度使用手机和短视频对儿童大脑发育及情绪调节造成负面影响,指出育儿方式正被算法“劫持”。文章强调,AI驱动的算法通过“爽感炸弹”取代真实体验,导致儿童情绪失控、思考能力受损,呼吁家长关注孩子与现实世界的互动。
分析:
它明确指出“我们的养育方式,正在被算法悄悄劫持!”,并详细描述了AI驱动的短视频算法对儿童大脑发育(“前额叶还在发育,杏仁核却天天‘加班’,情绪开关失灵了!”)和认知能力(“把‘思考权’一键外包!”)造成的负面“社会影响”。这符合高价值标准中“社会影响与伦理风险”的定义,揭示了AI应用在社会层面引发的深层问题。
正文:
#孩子玩玩手机就一辈子毁掉了吗?#千万别让孩子再这样玩手机了!家长们,我们真的错了吗?!
——不是孩子离不开手机,是我们的养育方式,正在被算法悄悄劫持!
你信不信?孩子刷15分钟短视频,大脑消耗的神经能量,等于跑完800米!可汗没流一滴,心却已过载——前额叶还在发育,杏仁核却天天“加班”,情绪开关失灵了!
你以为关掉通知就安全?错!更隐蔽的陷阱是:亲子共处时,你也在刷手机!
孩子偷看你屏幕的第37次,比你没收他手机的100次更伤——他学的不是规则,是“重要的人,总在看另一个世界”。
误区炸雷:买早教APP=重视教育?不!那是把“思考权”一键外包!
真正的大脑营养,是泥巴里的蚯蚓、雨后积水的倒影、拼图缺一块时憋红的小脸……可这些“慢信号”,正被0.5秒刷新的“爽感炸弹”永久静音!
所以今晚睡前,请摸摸孩子的手心——
是温热的、有汗的、攥着你手指的真实温度?
还是冰凉的、黏腻的、残留着屏幕指纹的虚无触感?
别等中考卷上写不出完整句子,才想起他三岁就学会了滑屏,却再没学会等待一朵蒲公英飘落……
主题分类:
社会影响与伦理风险
新闻 9: 机器人时代是否会导致大量失业 机器人时代是否会导致大量失业,这事儿众说纷纭。IMF提醒,AI会影响全球近40%的岗位,OECD称成员国平均高自动化风险职业约占28%。“人工智能教父”杰弗里·辛顿警告大规模失业可能到来,其他科技大佬也有类似激进预判。
不过,也有人觉得不会大量失业。企业引入机器和AI是
来源: 今日头条 - 自媒体
主题: 人工智能对就业市场的影响及潜在失业风险
摘要:
新闻探讨了人工智能和机器人时代是否会导致大规模失业的问题。国际货币基金组织(IMF)和经济合作与发展组织(OECD)的数据显示AI将影响全球大量岗位,而“人工智能教父”杰弗里·辛顿等专家也警告可能出现大规模失业。然而,也有观点认为AI会通过提升效率催生新需求和新岗位,真正受威胁的是流程化、经验型的岗位。
分析:
该新闻直接讨论了“机器人时代”和“AI”对“岗位”和“失业”的影响,引用了“IMF提醒,AI会影响全球近40%的岗位”、“杰弗里·辛顿警告大规模失业可能到来”等事实。这与高价值标准中的“社会影响与伦理风险”维度高度相关,因为它涉及AI引发的“失业”等社会问题。
正文:
机器人时代是否会导致大量失业 机器人时代是否会导致大量失业,这事儿众说纷纭。IMF提醒,AI会影响全球近40%的岗位,OECD称成员国平均高自动化风险职业约占28%。“人工智能教父”杰弗里·辛顿警告大规模失业可能到来,其他科技大佬也有类似激进预判。
不过,也有人觉得不会大量失业。企业引入机器和AI是为降成本、提效率,效率提升会催生新需求。真正危险的是把工作当“流程执行”、把经验当“记忆库”的岗位。岗位可能变少,但新的岗位也会冒出来,比如需要会设计流程、验收结果的人。
主题分类:
社会影响与伦理风险
新闻 10: 无标题
来源: 新浪微博视频 - 自媒体
主题: AI审判中的人为操控与公正性问题
摘要:
新闻提及杭州已实现AI审判,并引用《极限审判》的剧情,指出人们对AI公正性的认知可能被其背后的人为操控所颠覆,暗示AI审判的公正性面临挑战。
分析:
该新闻具有价值,因为它直接提及了“AI审判在杭州已成为现实”,并强调了“以为是AI的绝对公正,没想到背后藏着人为操控”这一关键信息。这触及了人工智能在司法等关键领域应用时可能出现的“社会影响与伦理风险”,特别是关于AI系统公正性、透明度及潜在“信任危机”的问题。
正文:
#AI审判在杭州已成为现实##被AI审判是什么体验# 《极限审判》的反转太绝了!以为是AI的绝对公正,没想到背后藏着人为操控,真相远比判决更震撼!
主题分类:
社会影响与伦理风险
新闻 11: 温故2025
来源: 微信 - 自媒体
主题: AI在个人职业发展与创业中的应用及对职场竞争力的影响
摘要:
该新闻是作者对2025年的个人总结,重点阐述了AI技术对其职业和个人生活的深远影响。作者详细描述了AI如何提升其工作效率、助力成功跳槽、开辟兼职机会(如AI辅助法务工作),并计划利用AI开发小程序以实现独立创业。文章还提及AI对职场竞争格局的改变,以及个人在面对AI时代挑战时,通过提升能力寻求独立发展的思考。
分析:
它触及了“社会影响与伦理风险”维度。作者在文中明确指出“AI越来越能替代我们的工作,换个角度想,我们加AI,是不是也可以替代越来越多的同事”,这直接反映了AI技术对职场生态和就业模式的潜在冲击,即“失业”风险和个体竞争力的重塑,符合高价值标准中关于AI引发的“失业”等社会问题的描述。
正文:
接着用下面这个模板,总结2025年:
1、2025年你最大的收获是什么?
答:2025年丰收之年,有五大收获:正式用上了AI、意外换到了新工作、多了份兼职、成功减肥、公众号流量主赚了点钱。
(1)正式用上了AI
之前用AI主要是图个新鲜,为了展示自己用上了AI。而今年,工作中已经全面用上了AI或AI思维,打开了新天地,极大的提高了工作效率,提升了职场竞争力。
比如现在基本用AI写方案,AI辅助我做面试准备,甚至于用AI分析领导特点。
现在的工作面试前就用了AI辅助,让我快速抓住了核心,再一次成功跨行。
我将领导常说的话,AI就帮忙总结出了现在的领导是:“结果导向、精于权术、防御心强。”
再提供我的特点,我们之间冲突和矛盾点之后,AI就分析了原因,给了我指导。
真是太强大了,我老是被精于权术,善于政治斗争的领导拿捏,一直在这个地方打转,手足无措。
现在好了,有了AI的指导,有了应对策略,自信心就上来了,帮我解决了多年的职场顽疾。
现在的领导年龄大,虽然精于权术,善于政治斗争,有经验,但他不会用AI,他以为的我,早已不是他昨天看到的样子,他面对是一个会用AI的下属。我的经验可能不是他的对手,但有了AI,我就没那么容易被拿捏了,至少AI给我提供了更多的防御和进攻策略,我不用再任人宰割了。
(2)意外换到了新工作
上一份工作虽然当上了运营总监,但我心里知道,这份工作不好!首先是业务做不起来,第二是公司文化不行,或者说我不喜欢特别强调“管理”的公司,因为这类公司大多是业务不行,所以大家拼命讲管理。而管理很大程度就是管人,这是我很不喜欢的模式,也是我非常不擅长的地方。
11月份,我第一次做成营销活动,突然掌握了C端做营销活动密码,心里高兴的不得了。结果会上就被老板骂活动没做好,其他同事也在那指指点点,这让我很不爽。
因为远程开会,老板在那骂,我就在投简历,没想到,第二天就通过AI辅助,找到了新工作。除了待遇,工作环境等更好外,新工作也更有希望,更简单,更能发挥价值。
我被骂的那次营销活动,是这个公司,目前为止,做的最好的,唯一做成功的营销活动,我走之后一个多月,他们谁也没再做成,包括那些指指点点,说的头头是道的同事。
而且很邪门的一点,我走当天,活动效果就开始断崖式下跌,我真没有操控这个结果,也有点暗爽的感觉。
(3)多了份兼职
这也是个意外之喜,我要离职,其他工作别人都能接,就是拟合同,审合同的这块工作别人接不了,没人具备这个能力。虽然这只是我顺带手,轻松能搞定的事,但别人就是干不好,按老板的说法,之前招过两个专职的法务,都没有我顺带手干得好。
我写出来的合同,简洁明了严谨,又有很强的可操作性,我不会一味的钻进法律“严谨”的框里。
基于这种情况,老板就让我接着干法务这些事,每月给我几千块钱,对公司来说,也划算,性价比最高,因为他很难招到我这么好用,又便宜的“法务”。
实际上,我主要用AI拟合同,审合同,也不费事,哈哈哈哈!
这里多说几句,有人可能会问,那为什么其他人不能用AI辅助,接手法务这事呢?
这就涉及另外一个问题了,把事情说清楚可不是一件容易的事,我们大多数人不具备这个能力,这是真的。你跟AI说不清楚事情,AI怎么会给你一个清晰的结果呢?
写公众号这些年,虽然没赚到什么钱,也没什么粉丝,但就是这种大量写,极大的提高了我的表达能力,让我能较容易的说清楚一件事,加上AI后,这就变成了一种比较优势。
就像,写公众号积累的是开车技术,现在又多了辆车,那我肯定会比光有车,但不会开车的人车得快。
(4)成功减肥
之前多次尝试过减肥,就是减不下来,心里已经放弃了,没想到通过16+8减肥法,3个月轻松瘦了20斤,而且还维持住了体重。
做成了一件之前想都不敢想的事情,而且还是轻松解决,真是太开心了,也彻底改变了我心底对“饿”,对“贪婪”的感觉,原来我可以不用“吃”“贪”这么多东西,还能让我有更好的身材,更舒服的身体状态,也更省钱。
对应的,人生的压力也就小了,加上工作上的意外收获,让我开始有了点从容,有点松弛的感觉,挺好!
(5)公众号流量主赚了点钱
这两篇文章都有两万多的阅读量,让我赚了几百块钱。
《减肥成功,非常开心!!!》
《研究发现:做好这3件事,抗衰老又延寿!每个人都能做到,免费又实用!》
加上这些年学到的写公众号技巧,这让我意识到,通过公众号文章赚点小钱已经变成了可能,至少对我来说,已经不是那么遥不可及。
之所以没有大量发文章,甚至比以前写的更少了,不是因为写不出来,而是我发现,有了AI辅助,我还能做更多,价值点更高的事情,我已经不满足于通过写公众号赚点小钱了,目标变了,也就是接下来要说的。
2、2025年你没放下的是什么?
答:没有完成“燃烧你的卡路里”微信小程序的研发和上线。
减肥成功的经验,以及相关文章阅读量高的数据,告诉我,或许可以做一款减肥的小程序,辅助一些人减肥。
12月份,我就用AI辅助,开始小程序的开发,只可惜一直卡在,通过豆包AI识别食物卡路里这个环节,很遗憾,暂时还没能攻克这个难题。
希望2026年能完成微信小程序的开发和上线,以及后面通过AI辅助做小程序营销,简单说,我想通过AI辅助,完成产品开发,流量获取,以及转化变现,也就是拥有一个属于自己的生意。
我也知道,这个项目不一定能成,很可能投入得多,赚的少,甚至赚不到钱,但对我来说,这不重要,重要的是尝试,掌握全链条的能力,扩大自己的能力边界。
就像我写了几百万字的公众号,看似没什么阅读量,没什么粉丝,更没什么收入,但这不重要,至少不是最重要的。
重要的是,我的能力提高了,这能让我能抓住更多的机会,也有点像提高了射击精度和射程,我能去挑战更远、更大的目标了。
马上四十了,接下来将会越来越难找到工作,而且我已经开始有职场的倦怠感,已经没那么想上班了,这就需要我尽快找到独立自主的生意,只有这样,我才能很潇洒的跟职场说拜拜!
也只有这样,当有一天找不到工作时,才不会饿死!
也只有这样,我的人生才能过的更惬意,对自己才会更满意!
3、2025年哪件事让你觉得自己很勇敢?
答:开始尝试用AI辅助开发微信小程序,而且心里已经盘算着,通过AI辅助引流和转化。
我看到英文就犯怵,更不用说编程了,这是我一直躲着的东西,现在有了AI辅助,我已经开始向这个内心恐惧点发起了进攻,而且已经看到了点曙光。
如果这事做成,或者做通了,那将扩大我的能力边界,要知道,很多事情之所以别扭,主要是想法太大,能力太小。提高能力是解决这种别扭最好的方式之一。
4、2025年哪件事让你觉得羞愧,恨不得清除记忆?
答:没有
5、2025年在人生中,处于什么阶段?
答:不停地掷骰子、焕发新生、豁然开朗、触手可及,看到了点黎明前的曙光。
(1)不停地掷骰子
选择大于努力,像我这种没有家庭、学校、能力背景的三无人员,更需要通过不停的选择,让自己获得更好的机会。
可是,每次选择都有点像掷骰子,当拿到的是低点数,就要想办法尽快再掷,争取拿到更大的点数,并停留更长的时间,进而拿到更多的收益。
(1)焕发新生
豁然开朗、触手可及,看到了点黎明前的曙光,这都是AI带来的,确实让我焕发了新生,提高了职场竞争力。
AI越来越能替代我们的工作,换个角度想,我们加AI,是不是也可以替代越来越多的同事,进而替代老板,替代公司?
虽然这条我还没有走通,还没走成,但我已经看到了黎明前的曙光,已经感受到了,那些之前想都不敢想的事情,正在变得触手可及。
6、2025年你的生活用一句歌词概括是什么?
答:已经很久不听歌了,总体上说,生活上平淡中透着幸福!
我跟老婆认识和结婚快十年了,幸福和谐!
三岁的女儿特别可爱,给我们带来了无穷无尽的欢乐和幸福!
岳父母承包了楼下小象超市的纸盒,加上岳母在里面打扫卫生,他两每个月加起来能赚一万多,他们有了收入,跟我们在北京住起来也开心,也不会想着回老家或者给大舅子带孩子。
岳父母每天从早上四五点,忙到晚上十点,虽然辛苦点,忙一些,但在我看来挺好的,忙着反而事少,身体也好,闲了反而会有更多的麻烦事。
7、2025年你的年度成语是什么?
答:先抑后扬
11月之前,都在上一份工作的漩涡里,我很清楚的知道,我自己深处在漩涡里,再怎么挣扎都没有用,最好的方式是装死,忍耐,积蓄力量,顺着漩涡出来,而不是对抗。
所以不管是主动降薪,还是接受工作内容,岗位的调整都是这套策略中的具体战术,好在上天垂怜,让我在11月份意外的找到了一份更有前途和希望,待遇更好的工作。
还想说说写公众号带来的机会,上面也提到了,这让我收获了一份法务兼职工作,其实这之前,要不是我拟合同的能力上超群,我即使主动降薪,接受工作内容和岗位的调整,公司也一样会裁掉我。总结的说,人生没有白走的路,每一步都算。
8、2025年你最开心的时刻是?
答:2025年,除了上面说的,实实在在的收获让我开心外,还有一件事让我很开心,虽然这事没成。
7月30日,一个刚换工作不久的朋友问我,有没有兴趣跟着他干?
那当然愿意了,不说当时的我处于水深火热之中,即使今天或以后,只要有这样的机会,我也会慎重考虑。
这个朋友是高考状元,清华的本硕博,他所在的公司都是好公司,这不仅仅是好工作的问题,而是进入另一片天地,加上朋友的见识,能帮我打开另一扇天窗。
只是很可惜,由于跨度太大,朋友的内推,最终没成。
但我依然很开心,因为能得到这样朋友的认可,像一缕阳光照进我未敢全然自信的角落——它不仅悄然提高了我的自我认同,更成了我心底一声温暖的回响:“你看,你这人不错!不然这么高水平的朋友,怎么可能会认可你呢?”
9、2025年你最沮丧的时刻是?
答:肯定是朋友的这次内推没成,没能进入另一片新天地,一个认知新高地。
这里确实有沮丧,但对我来说,还是很有收获,因为这次机会,让我看到了另一片天地,虽然没进入,但看到了。
在认真准备面试的时候,通过AI协助,也梳理清楚了我的优势,豁然开朗,对于找到现在的工作很有帮助。
这有点像,一个人干了一件事,事本身是没成,但是认识了几个新朋友,知道了下一个新机会。新机会,他也去干了,但也没成,但是掌握了一些新资源。想用这些资源去干点什么,也不顺利,但是顺手掌握了一些新知识。看起来这个人很鲁莽,到处撞南墙,但每一次撞,总会有一些意外收获,这些意外收获最后给他拼出了一条道路。
没必要盯着一个点,一个所谓的结果看,只要生命还在延续,就要从演化的视角看待问题,更多的考虑这个事情,能给后续的路带来了多大助力?怎么用好这个助力?让自己走的更快、更好、更轻松!
10、2026年你的第一个具体计划是什么?
答:希望通过AI辅助,做成“燃烧你的卡路里”微信小程序,并推向市场,跑通商业模式。
马上四十了,除了后续很难找到工作外,还要考虑年龄带来的身体变化,看到一些资料,人不是线性衰老,45岁左右,体力和智力都有可能出现一波断崖式衰老,时间不多了,需要争分夺秒,早点拥有自己的生意。
=========================
1、《温故2019》
2、《温故2020》
3、《温故2021》
4、《温故2022》
5、《温故2023》
6、《温故2024》
主题分类:
社会影响与伦理风险
新闻 12: 脑机接口概念潜力股票梳理
来源: 今日头条 - 自媒体
主题: 中国脑机接口(BCI)产业发展、相关概念股票投资分析及潜在风险评估
摘要:
新闻梳理了中国脑机接口(BCI)作为“未来产业”在政策支持下加速发展的现状,并按产业链环节系统性地分析了相关潜力股票,涵盖医疗应用、硬件与芯片、消费级与场景应用等领域。文章详细列举了各公司的核心逻辑、市场表现及潜在风险,包括技术、审批周期、伦理与隐私问题,并提供了投资策略建议。
分析:
它明确提到了“伦理与隐私:脑数据采集可能引发监管收紧”这一风险,直接触及了AI/BCI技术发展中可能出现的“社会影响与伦理风险”问题。此外,新闻指出BCI是“未来产业”并获得“中国七部门联合发文重点支持”,显示了其在国家战略层面的重要性,可能引发未来更广泛的社会和监管讨论。
正文:
截至2025年12月,脑机接口(Brain-Computer Interface, BCI)作为“未来产业”已被中国七部门联合发文重点支持,产业化进程明显提速。结合政策、技术突破、临床进展、产业链布局及市场表现,以下是对
脑机接口概念潜力股票
的系统梳理,按产业链环节分类,并附核心逻辑与风险提示:
一、医疗应用龙头(业绩确定性高)
1.三博脑科(301293.SZ)
核心逻辑
:国内唯一获脑机接口临床植入许可的民营神经专科医院集团;与清华合作“睿米”手术机器人(精准度92.7%);2024年完成200+例半侵入式植入手术,单例收费约50万元。
催化点
:医保纳入预期、福建三博完成介入式BCI试验。
2.创新医疗(002173.SZ)
核心逻辑
:参股博灵医疗40%,其“BCI-4000全植入系统”已进入III期临床,对标Neuralink,聚焦渐冻症、癫痫治疗。
市场表现
:2025年涨幅超85%,近一年涨停16次。
3.爱朋医疗(300753.SZ)
核心逻辑
:非侵入式医疗级龙头,拥有3张医疗器械注册证,“CSI脑状态指数算法”用于麻醉/睡眠监测;控股朋睿脑科学布局ADHD训练系统。
风险提示
:2025年三季报净利润为负,短期承压。
二、硬件与芯片龙头(技术壁垒高)
4.高德红外(002414.SZ)
核心逻辑
:子公司衷华脑机研发出
65,000通道脑机芯片
(Neuralink仅3,072通道),全球领先;2025年Q1净利润同比暴增896.56%。
定位
:上游核心器件国产替代标杆。
5.汉威科技(300007.SZ)
核心逻辑
:柔性脑电传感器成本比美产低50%,已规模化生产;中标工信部“关键器件”专项;供货华为、特斯拉。
市场表现
:2025年股价翻倍(+100%+)。
6.美好医疗(301363.SZ)
核心逻辑
:人工耳蜗等神经植入部件代工企业,切入侵入式BCI上游供应链。
业绩
:2025年Q3营收11.94亿元,行业排名第14。
三、消费级与场景应用龙头(成长空间大)
7.岩山科技(002195.SZ)
核心逻辑
:联合华山医院开发脑电大模型,实现中文语义精准识别;SSVEP延迟仅60ms;与华为合作“意念操控《黑神话:悟空》”。
风险
:市场情绪波动大,有投资者抱怨“未回本”。
8.科大讯飞(002230.SZ)
核心逻辑
:AI+脑科学融合,脑电情绪识别准确率92%;脑控智能音箱已落地;教育脑机订单占比超60%。
9.翔宇医疗(688626.SH)
核心逻辑
:非侵入式康复设备商业化推进中;与天津大学等共建国家级项目;计划打造“脑机接口治疗中心”。
机构关注
:2025年8月接受9家机构调研。
10.佳禾智能(300793.SZ)
核心逻辑
:布局脑电波传感器+可穿戴设备,成立脑科学事业部;切入智能家居与休闲娱乐场景。
业绩
:2025年Q3营收16.25亿元,但毛利率承压(14.85%)。
四、其他值得关注标的
公司
代码
亮点
乐普医疗
300003.SZ
“BCI+VR+AI+机器人”康复系统,建示范基地
世纪华通
002602.SZ
游戏场景落地,出海收入占比90%
昆仑万维
300418.SZ
AIGC+脑机接口消费应用
博拓生物
688767.SH
参股浙大侵入式BCI团队,技术储备强
麦澜德
688273.SH
非侵入式聚焦运动康复(截至2025.12.11)
五、风险提示
技术风险
:侵入式长期安全性待验证,非侵入式信号精度有限。
审批周期长
:医疗器械认证通常需3–5年,影响业绩兑现节奏。
伦理与隐私
:脑数据采集可能引发监管收紧。
估值泡沫
:部分个股短期涨幅过大,存在回调压力。
六、投资策略建议
短线
:关注政策节点(如地方细则、大会召开)、Neuralink进展、技术面回踩机会。
中长线
:优选脑机业务占比≥20%、机构重仓、有产品落地能力的企业。
分散配置
:可考虑通过
脑机接口主题ETF
(若已发行)或组合持仓降低个股风险。
结语:2025年是脑机接口从“主题炒作”迈向“业绩兑现”的关键拐点。医疗康复率先落地,消费电子、教育、游戏等场景将接力爆发。万亿赛道已启航,布局正当时。
主题分类:
社会影响与伦理风险
新闻 13: 科研动态|丁彦青教授、卞修武院士团队开发甲状腺结节的细胞学分类诊断深度学习模型——AI-TFNA
来源: 今日头条 - 自媒体
主题: 人工智能在甲状腺结节诊断中的应用与效能提升
摘要:
南方医科大学、陆军军医大学与新加坡科技局合作开发了新型人工智能模型AI-TFNA,用于甲状腺结节的细胞学分类诊断。该模型融合深度学习与机器学习技术,遵循国际标准,通过多样化数据训练和多中心验证,显著提升了病理医师的诊断准确率(初级提升7.83%,高级提升2.68%)和效率(约2倍),并具有强大的泛化能力。AI-TFNA有望减少误诊和过度治疗,缓解中国医疗资源分布不均及病理医生短缺问题。
分析:
它直接涉及利用人工智能技术“缓解中国当前面临的医疗资源分布不均及病理医生严重短缺的现实问题”,并通过“减少主观差异,降低误诊和过度治疗风险”来解决医疗领域的“社会问题”,提升了“甲状腺结节临床诊断的准确率与效率”。这符合高价值标准中“社会影响与伦理风险”维度,即AI对社会问题和福祉的积极影响。
正文:
近日,南方医科大学南方医院、金凤实验室丁彦青教授团队,陆军军医大学西南医院、金凤实验室卞修武院士团队与新加坡科技局(A*STAR)余维淼教授团队合作在国际期刊Advanced Science上发表了题为“Cytological Classification Diagnosis for Thyroid Nodules via Multimodal Model Deep Learning”的研究性论文,成功开发出一种新型人工智能模型——AI-TFNA,该模型有望显著提升甲状腺结节的诊断精准度与临床管理效率。
甲状腺结节是一种常见的内分泌系统疾病,影响全球超过60%的普通人群,在女性中尤为高发。大多数甲状腺结节为无症状的良性病变,但有5%至17%的病例最终被证实为恶性。根据世界卫生组织国际癌症研究机构发布的2022年数据,甲状腺癌已位列全球第七大常见恶性肿瘤,且其发病率正呈现快速上升趋势。这一增长主要归因于两方面因素:一是环境污染和长期电离辐射暴露导致的甲状腺癌实际发病增加;二是由于诊断工具的灵敏度和检测技术的进步,使得更多病例得以被发现。值得注意的是,在甲状腺癌发病率迅速攀升的同时,其死亡率却维持在较低水平,这一差异部分源于临床上对甲状腺结节可能存在的误诊及过度治疗现象。
研究团队成功开发了AI-TFNA模型,该模型创新性地融合了深度学习与机器学习技术,并严格遵循国际通用的甲状腺细胞病理学Bethesda报告系统(TBSRTC)标准,可为甲状腺结节细胞学诊断提供客观、可重复的AI辅助工具,有助于减少主观差异,降低误诊和过度治疗风险。
亮点一:多样化的数据收集,以实现稳健模型的开发与验证
该研究共收集了20803份来自中国不同地区的7个医疗中心的甲状腺液基细胞学样本用于模型的训练、验证及测试。考虑到现实环境中遇到的可变性并确保模型的泛化能力,每个医疗机构都实施了不同的玻片制备和染色技术,并使用不同型号的扫描仪形成全视野数字切片图像(WSI)。
亮点二:AI-TFNA提高病理医师的诊断准确率及效率
在AI-TFNA的辅助诊断实验中,初级细胞病理学家的诊断准确率提升了7.83%,诊断效率提高了约1.93倍;高级细胞病理学家的平均准确率提高了2.68%,效率提高了约2.04倍。
亮点三:全面的内部和外部验证证实了AI-TFNA在不同临床环境中的诊断准确性和可靠性
1.模型性能的评估:108517张内部机构的WSI和2153张外部机构的WSI用于测试AI-TFNA在不同的玻片制备方法(BD SurePath、ThinPrep)、染色技术(巴氏染色、HE染色)以及不同的扫描方式(扫描设备:滨松、徕卡、生强、江丰、优纳;扫描倍数:20、40)各临床场景中的性能,结果显示AI-TFNA具有较强的泛化性。2.多模态融合模型的评估:将BRAF突变预测模型与诊断模型相结合,可修正错误分类。
亮点四:通过图像外观迁移进一步提升模型的泛化能力
该研究采用了图像外观迁移(IAM)方法在多中心数据集上进行验证,灵敏度提升1.90%,特异性提升8.12%,这表明即便在不同机构间存在差异的情况下,AI-TFNA也具备实现稳定性能和普遍适用性的潜力。
AI-TFNA 严格按照TBSRTC的诊断标准设计,从细胞标注阶段到最终决策环节,均采用了人工智能技术,整合了细胞数量、细胞核/膜形态、纹理等相关特征,以提高准确性和临床适用性。其中VAN-tiny 模型组件能够有效应对复杂的临床情况,能够准确区分甲状腺滤泡上皮细胞的良性与恶性,并能精确区分滤泡上皮细胞与巨噬细胞。由此可见,AI-TFNA 在提升甲状腺结节临床诊断的准确率与效率方面具有重要价值,同时有望缓解中国当前面临的医疗资源分布不均及病理医生严重短缺的现实问题。
主题分类:
社会影响与伦理风险
新闻 14: 太好玩了,网友拿着B超单问豆包小孩性别,
这脑洞怎么想出来的,
刷到一个网友的视频,他拿着在医院拍的B超单问豆包胎儿性别,怕被豆包拒绝还谎称孩子已经生了,就想验证下,这位网友还是有点小聪明的。
其实大家都知道B超单的作用只在于监测胎儿的健康情况,不存在分辨性别的功能,医院也有明文规定,禁止非医学的
来源: 今日头条 - 自媒体
主题: 用户尝试利用AI进行胎儿性别鉴定及其伦理边界
摘要:
一位网友试图通过向AI聊天机器人“豆包”提供B超单来询问胎儿性别,甚至为此编造谎言以避免被拒绝。新闻指出B超单不具备性别分辨功能,且医院明文禁止非医学的胎儿性别鉴定,并提及当前社会对生男生女的观念已趋于开放。
分析:
该新闻具有价值,因为它涉及用户尝试利用AI(“豆包”)进行伦理敏感的胎儿性别鉴定。用户“怕被豆包拒绝还谎称孩子已经生了”的行为,反映了用户试图规避AI在处理“禁止非医学的胎儿性别鉴定”等社会伦理问题时的限制,这凸显了AI在社会应用中可能引发的“社会影响与伦理风险”,以及AI系统在维护伦理规范方面的挑战。
正文:
太好玩了,网友拿着B超单问豆包小孩性别,
这脑洞怎么想出来的,
刷到一个网友的视频,他拿着在医院拍的B超单问豆包胎儿性别,怕被豆包拒绝还谎称孩子已经生了,就想验证下,这位网友还是有点小聪明的。
其实大家都知道B超单的作用只在于监测胎儿的健康情况,不存在分辨性别的功能,医院也有明文规定,禁止非医学的胎儿性别鉴定,要看性别也只有真在做B超的医生可以看出来。
现在人们思想已经开放了,生男生女已经没那么重要了,现在一家一个女孩的大有人在,不像过去跟家里有皇位继承似的,一定要生出男孩来,为了满足自己的好奇心也是不用其极了,
也挺搞笑的,网友的脑洞永远在刷新我的认知,
你还见过那些网友的骚操作?评论区聊一聊。
主题分类:
社会影响与伦理风险
新闻 15: 一张礼品卡导致苹果用户丢失所有iCloud信息
来源: 微信 - 自媒体
主题: 科技巨头算法决策的负面影响与用户数据主权
摘要:
一位资深苹果开发者因一张问题礼品卡,其Apple ID被苹果公司关闭,导致他丢失了数TB的iCloud数据、已购软件和数字身份。苹果客服拒绝提供具体原因,并建议他重新注册账号,引发了对科技巨头“黑箱算法”和“系统性冷漠”的广泛质疑,以及用户数据主权丧失的担忧。文章指出,这反映了科技巨头对AI和自动化的过度依赖所带来的“算法暴政”。
分析:
它直接讨论了“科技巨头对自动化的过度依赖”以及“AI 和自动化技术的普及”所带来的“算法暴政”和“系统性冷漠”,导致用户“信任的崩塌”和“用户数据主权的彻底丧失”。这符合高价值标准中“社会影响与伦理风险”维度,即涉及AI引发的“算法歧视”、“偏见”等社会问题,以及造成社会“信任危机”。
正文:
因为误用了一张有问题的礼品卡,一位资深果粉被苹果公司处以“数字极刑”,无法访问存在iCloud中数TB的家庭照片和个人数据。
在科技圈和数码爱好者中,有一类人被称为“布道型果粉”。他们不仅是忠实用户,更是生态的建设者,用代码和著作将一家公司的技术推向神坛。
Paris Buttfield-Addison 博士就是这样一位典型的“果粉”兼技术专家。作为一名计算机科学家、屡获殊荣的游戏开发公司联合创始人,他撰写了多本关于 Objective-C、Swift 语言和 iOS 开发的专业书籍。可以说,他的整个职业生涯都建立在苹果的生态系统之上。
然而,就是这样一位为苹果摇旗呐喊多年的资深开发者,最近却因为一张价值 500 美元的礼品卡,被苹果判处了“数字死刑”。
被“炮决”的高端果粉
悲剧的起因荒谬得令人难以置信。
为了支付自己高达 6TB 的 iCloud+ 存储空间费用,Buttfield-Addison 博士在一家大型实体零售店购买了一张 500 美元的 Apple 礼品卡。当他试图充值时,系统提示失败。在与零售商沟通后,对方表示代码可能被盗用,并为他重新发行了代码。
就在他以为问题解决之时,噩梦开始了。
他的 Apple ID 突然被标记为“根据 Apple 媒体服务条款和条件已关闭”。这一举动产生的连锁反应是毁灭性的“炮决”:
通讯断绝:他被踢出了 iMessage,无法与外界正常联络。
资产清零:价值数千美元的已购软件和媒体内容瞬间化为乌有。
记忆抹除:存储在 iCloud 服务器上的数 TB 家庭照片和个人文件无法访问。
设备变砖:他的 iPhone、iPad、Apple Watch 和 Mac 无法同步、更新,基本功能瘫痪。
“我的核心数字身份被切断了,”Buttfield-Addison 在博客中绝望地写道,“为了这家公司的技术,我实际上做了一辈子的苹果布道者。”
傲慢的黑箱算法
如果说封号是因“风控”算法的误伤,那么苹果随后的应对则展示了科技巨头典型的“系统性冷漠”。
当 Buttfield-Addison 试图申诉时,他撞上了一堵由标准话术和不可解释性构成的墙。苹果客服拒绝透露封号的具体原因,并冷冰冰地表示“升级处理也不会有不同的结果”。
更令人啼笑皆非的是,一位苹果高级顾问给出的解决方案竟然是:“重新注册一个新账号。”
对于普通用户来说,这也许只是换个马甲;但对于一位拥有开发者账号的专业人士来说,这无异于自杀。Buttfield-Addison 指出,这种试图“绕过”禁令的行为极有可能导致他的开发者资格被永久列入黑名单,彻底断送他的职业生涯。
截至目前,尽管他已联系到苹果的高级公关团队,但解封的希望依然渺茫。Buttfield-Addison 坦言,即使账号最终被恢复,这种信任的崩塌也是不可逆的。他已经决定逃离——将笔记本换成 Linux,手机换成 Android。“即使修复了,我也会尽快离开。我是认真的。”
数字封建时代的“农奴”:你的数据不属于你
Buttfield-Addison 的遭遇并非孤例,近期 YouTube 基于算法误封 Windows 11 攻略视频的闹剧也如出一辙。这背后折射出两个令人不安的深层问题:科技巨头对自动化的过度依赖,以及用户数据主权的彻底丧失。
算法暴政与客服的消失
随着 AI 和自动化技术的普及,巨头们为了削减成本,将原本应由人类进行的复杂判断交给了算法。这导致了“有罪推定”的常态化——只要算法觉得你有问题(比如兑换了一张涉嫌欺诈的礼品卡),你就必须在没有法庭、没有律师、甚至没有明确罪名的情况下接受“极刑”。对于拥有话语权的大V尚且如此,普通用户若是遭遇此类误封,往往只能在客服机器人的死循环中绝望。
我们从未真正拥有过数据
这一事件最恐怖之处在于它揭示了一个真相:在云时代,你并不拥有你的生活。
不管是珍贵的家庭相册,还是斥资购买的数字内容,只要它们存储在封闭的生态系统中,所有权实际上就属于平台。我们支付的高昂费用,仅仅是购买了一项随时可能被单方面终止的“租赁服务”。
苹果通过硬件与服务的深度绑定,构建了极其稳固的商业护城河。这种垄断地位赋予了它对用户数字命运的“生杀予夺”大权。当苹果公司决定切断你的 iCloud 访问权限时,实际上是没收了你的私有财产,而目前缺乏有效的法律框架来制约这种数字霸权。
Buttfield-Addison 博士的遭遇是对所有生活在“苹果园”里的人的一记警钟:当便利性成为唯一的追求,我们便不知不觉地交出了通往自己数字生活的唯一钥匙。
在万物互联的今天,如果你的数据主权不掌握在自己手中,那么你引以为傲的数字生活,不过是建立在沙滩上的城堡,巨头的一个浪头打来,便荡然无存。
参考链接:
https://hey.paris/posts/appleid/
相关阅读
苹果爆出“超级漏洞”:官方播客沦为黑客攻击入口欧盟迫使苹果采用新WiFi标准,安卓手机也能用AirDrop三星、苹果手机曝严重漏洞,成间谍软件重点目标
主题分类:
社会影响与伦理风险
新闻 16: 深圳街头机器人拳击震撼韩国制片人,中国科技崛起背后的人才战
来源: 今日头条 - 自媒体
主题: 中国科技崛起与人才战略,以及韩国科技人才流失的对比与反思
摘要:
一位韩国制片人访问深圳后,对中国在机器人拳击、无人驾驶等AI相关领域的科技进步和系统化人才培养战略深感震撼。文章对比了韩国理工科人才因研究环境恶化和就业前景黯淡而大量流失、学生放弃科学转投医学的现状,对韩国在未来科技竞争中的竞争力表示担忧。
分析:
它直接讨论了AI技术发展背景下,韩国因“研究环境恶化和就业前景黯淡”导致“理工科人才正在大量流失”的社会问题,这符合“社会影响与伦理风险”的高价值标准。
正文:
深圳街头机器人拳击震撼韩国制片人,中国科技崛起背后的人才战略秘密
我站在深圳的街头,看着无人驾驶出租车在车流中自如穿梭,旁边几个机器人正在进行激烈的拳击对抗。那一刻,我内心震撼不已——这还是我们印象中那个技术落后的中国吗?城市的空气中弥漫着一种我从未感受过的科技活力。
作为《人才战手》纪录片的制片人,我带着固有的偏见踏上了这次调研之旅。此前,我们接触到的中国消息大多是刺激性的负面事件,总觉得他们要追上我们还早着。但当我真正置身其中时,才发现我们对这个邻国的认知有多么浅薄。
中国的科技崛起绝非偶然。我在当地亲眼见证了他们教育体系的严密布局——从小学到大学,每个阶段都设有精准的人才筛选机制。被选中的学生会被定向培养,最终成为国家急需的尖端技术人才。这种系统化的举国动员政策,让他们的技术实力实现了质的飞跃。
更令我震惊的是,中国不仅在人工智能领域取得突破,他们的高铁网络、量子通信、航天工程同样领先世界。这些成就的背后,是无数年轻人在实验室里的默默付出,是整个教育体系对科技创新的全力支撑。
反观我们韩国的情况却令人担忧。现在许多家长愿意花费1亿韩元的家教费,只为让孩子进入医学院。我曾询问身边的朋友,如果花这笔钱能确保孩子成为医生,你会犹豫吗?几乎所有人都选择了肯定的答案。
数据显示,SKY大学自然科学类统招合格者中有43%放弃了原本的专业,转而投身医学复读大军。那些曾经立志从事科学研究的年轻人,面对现实的残酷,也不得不在6月中旬开始新一轮的复读冲刺。连普通的上班族都加入了这场竞争。
更让人痛心的是,我们仅存的理工科人才正在大量流失。由于研究环境恶化和就业前景黯淡,越来越多的工科毕业生选择出国发展。当专注工程技术的中国在科技战场上节节胜利时,我们的时间究竟流向了何方?
当我回到韩国,面对这场无声的技术竞赛,我们的时间还将流向何方?答案就在每一个选择的当下。
主题分类:
社会影响与伦理风险
新闻 17: OpenAI揭秘Sora:4人28天速成,85%代码由AI编写
来源: 独立网站
主题: AI在软件开发中的应用、人机协作模式及其对未来工作和就业的社会影响。
摘要:
OpenAI仅用4名工程师和28天便开发出Sora安卓版APP,其中85%代码由AI(Codex)完成。该案例展示了高效的“人机协作”模式,工程师负责架构和设计,AI负责具体编码,显著提升了开发效率和产品质量。新闻深入探讨了AI对未来工作模式和就业的深远影响,引发了关于AI是否会取代人类工作的讨论。
分析:
该新闻具有高价值。它详细描述了AI在软件开发中实现“85%的代码由AI编写”的突破性应用,并深入探讨了这种“人机协作”模式对“生产力革命”的推动,以及AI可能引发的“失业”、“抢饭碗”等“社会影响与伦理风险”。文章通过“网友热议”部分直接讨论了“程序员这碗饭还怎么端啊?”和“感觉明天就要被优化了”等关于AI对就业冲击的担忧,符合高价值标准中“社会影响与伦理风险”的定义。
正文:
工欲善其事,必先利其器。
在这个唯快不破的时代,效率就是生命,工具就是那个能让你弯道超车的加速器。以前我们总以为,要干大事得靠人海战术,得靠没日没夜的加班苦熬。但今天这个故事可能会彻底颠覆你的认知:当人类的智慧加上AI的执行力,所爆发出的能量,早已不是“一加一等于二”那么简单,而是一场惊心动魄的生产力革命。
咱们今天不聊虚的,就以此前科技圈炸了锅的一件事儿跟大伙儿唠唠。OpenAI这帮人,那是真敢想也真敢干。为了把那个能生成视频的Sora搞个安卓版APP出来,你猜他们用了多少人?仅仅4个人!这要搁在传统互联网大厂,这不得拉个几十人的团队,开无数个会,扯无数次皮?但这“四大金刚”仅用了28天,硬是把这APP给“手搓”了出来,而且一上线就霸榜谷歌Play Store。这背后的秘密说出来吓你一跳——85%的代码,竟然都是AI自己写的!
这事儿听着是不是有点像天方夜谭?但它就在咱们眼皮子底下发生了。
咱们得把时钟拨回到10月初。那时候Sora在苹果手机上已经火得一塌糊涂,安卓这边的用户早就急红了眼,谷歌商店里的预注册人数那是蹭蹭往上涨。这时候摆在OpenAI面前的是一块难啃的硬骨头:安卓机型千奇百怪,系统版本五花八门,要在一个月内搞定一个高质量的APP,换谁谁头大。
按照咱们惯常的思维,这时候是不是得赶紧招人?把各路编程大神都喊来救火?但懂行的人都知道,这软件开发里有个著名的“布鲁克斯定律”:你要是给一个已经延期的项目强行加人,只会让它死得更惨。为啥?人多了嘴杂,沟通成本那是指数级上升,本来一个人能干完的活,三个人干可能就得打架。
OpenAI这帮人脑子就是活,他们反其道而行之。不加人,加AI!他们组建了一支只有四名工程师的“特种部队”,给每个人都配了一个超级助手——AI智能体Codex。这哪是写代码啊,这简直就是指挥千军万马。
这28天里发生的事,真叫一个精彩。这四位工程师,摇身一变成了“包工头”。他们不再是那个天天对着屏幕敲代码敲到手抽筋的“码农”,而是变成了发号施令的架构师。他们只负责定规矩、画蓝图、搞设计,剩下的那些繁琐的、重复的、枯燥的搬砖活儿,统统甩给了Codex。
你别以为这AI就是个只会复制粘贴的傻瓜。在OpenAI内部,这Codex已经进化成了一个“懂事”的高级工程师。它不仅能写代码,还能自己给自己查错,甚至能根据你的要求给出好几套方案让你挑。咱们打个比方,以前盖房子,工程师得自己去砌每一块砖;现在好了,工程师只要说一句“这儿给我起一面墙,要多高多厚”,Codex“哗”地一下就把墙给你砌好了,又快又平整。
当然,这中间也不是没出过岔子。刚开始,工程师试着当甩手掌柜,直接跟AI说:“照着苹果版的代码,给我整一个安卓版的。”结果呢?翻车了。Codex写出来的东西虽然能跑,但那用户体验简直没法看,就像是拿英文强行翻译成中文,读着那叫一个别扭。这让大伙儿明白了一个理儿:AI再牛,它也是个没得感情的机器,它不懂什么叫“手感”,不懂什么叫“丝滑”。
于是,这帮人琢磨出了一套“人机合一”的新打法,他们管这叫“氛围流工程”。啥意思呢?就是把AI当成一个刚入职但能力超强的新员工来带。你要给它立规矩,告诉它咱们的代码风格是啥样的,架构是怎么设计的,哪里是雷区不能踩。甚至他们在代码库里到处贴“小纸条”(AGENTS.md文件),就为了随时提醒AI:“哎,这块儿得这么写,别搞错了!”
这么一来,效率直接起飞。遇到那种超复杂的逻辑,工程师先让AI去读文档,让它把逻辑理顺了,出一个计划书。工程师一看,嗯,这计划靠谱,再点头让它开干。这一套组合拳打下来,不仅速度快,质量还奇高。那APP上线后,无崩溃率竟然达到了99.9%,这质量,让多少大厂的几十人团队脸红?
最逗的是,这项目忙到飞起的时候,工程师们常常是一人开着好几个AI对话窗口。这边让AI 1号写播放功能,那边让AI 2号搞搜索模块,还有个AI 3号在后台修Bug。这哪里是在干活,这分明是在玩“多线程操作”的游戏嘛!这四个人,硬是活成了一支军队。
这事儿给咱们的启示太大了。以前我们总担心AI会抢饭碗,会让人没地儿站。但你看这OpenAI的实战,AI抢走的只是那些没技术含量的苦力活。它反而把人从繁重的体力劳动中解放了出来,让咱们能腾出手来去思考架构,去打磨体验,去搞那些真正需要人类智慧和情感的东西。这就是科技向善的力量,它不是来消灭人的,是来武装人的。
就像那位设计师说的:“Codex简直就是我工位上的神队友,不管我在哪,它都在。”这种人机协作的模式,才是未来工作的常态。咱们不再是单纯的执行者,而是成为了驾驭工具的决策者。这不仅是对生产力的解放,更是对人本身价值的一次升华。
网友热议:
网友“发际线保卫者”: “好家伙,4个人干了几十人的活,那剩下的那几十人是不是都要失业了?这以后程序员这碗饭还怎么端啊?看得我瑟瑟发抖,感觉明天就要被优化了。”
回复: 老铁,这种焦虑咱都能理解,毕竟谁也不想被时代抛下。但你换个角度想,汽车出来的时候,马夫是失业了,但司机的需求不是更多了吗?这事儿其实是在倒逼咱们升级。以后那种只会简单的“搬砖”代码的人确实危险了,但那种懂业务、懂架构、能指挥AI干活的“超级个体”,那可是香饽饽啊!咱们得赶紧把这新工具学起来,哪怕成不了那4个大神,起码别当那个只会砌砖的苦力,你说是不?
网友“代码洁癖患者”: “AI写的代码能看吗?虽然说是99.9%无崩溃,但我总觉得机器生成的代码肯定是一坨乱麻,维护起来估计得火葬场。我看这也就是为了赶进度,后期还得人来填坑。”
回复: 兄弟,你这是行家看门道啊!确实,如果放任AI瞎写,那代码肯定没法看。但你没注意文章里说的吗?人家那是“先立规矩后干活”,有人类工程师在旁边像盯着徒弟一样盯着呢,架构、规范那都是人定的。这就好比你让大师傅把关,徒弟掌勺,味道差不到哪去。再说,现在这技术迭代多快啊,咱们不能老拿老眼光看新事物,说不定过两年AI写的代码比咱们手写的还规范呢!
网友“吃瓜群众007”: “这不就是那个‘我来组成头部’的现实版吗?不过说真的,这APP好用吗?别光吹技术牛,要是用户体验不好,那也是白搭。AI懂什么叫人性化设计吗?”
回复: 这话说到点子上了!技术再牛,最后还是得服务人。所以OpenAI那帮工程师才没敢当甩手掌柜啊,体验层面的东西全靠他们自己上手调。AI负责把功能跑通,人负责把体验搞顺。这就好比AI负责把菜炒熟,人负责最后的摆盘和调味。这才是“人机合一”的精髓嘛,没了人的那点灵气儿,再牛的代码也是冰冷的。
网友“卷王之王”: “才28天?这是真的不要命啊。虽然有AI帮忙,但这4个人估计也是没日没夜地干吧。科技进步是好事,但这节奏是不是太快了点?感觉人都要被机器推着跑了。”
回复: 哎,一声叹息啊。这确实是现在的现状,“中国速度”也好,“AI速度”也罢,背后都是一个个鲜活的人在拼搏。咱们歌颂效率的同时,确实也不能忽视了人的身心健康。不过话说回来,如果有趁手的工具能帮咱们把8个小时的活儿压缩到2个小时干完,那剩下的时间咱们是不是就能多陪陪家人,多享受下生活了?关键还是看咱们怎么用这个工具,是让它把咱们卷死,还是让它帮咱们躺平,这可是个大智慧。
看着这4个人用28天创造的奇迹,咱们是不是该反思一下:在这个AI加速狂奔的时代,我们是该恐惧地抱残守缺,还是该勇敢地跳上这列高速列车,去成为那个驾驭AI的“超级个体”?当一个人的战斗力能顶一支军队的时候,你准备好做那个指挥官了吗?
对此你怎么看?欢迎评论区留言讨论~
(参考信息来源:4人28天手搓Sora APP,约85%代码竟是AI写的!--新智元)
主题分类:
社会影响与伦理风险
新闻 18: 又翻车!媒体称赞39岁无腿外卖员很励志,却被网友怒批!
来源: 今日头条 - 自媒体
主题: 媒体对残疾外卖员“励志”报道引发的社会伦理争议与平台算法剥削问题
摘要:
媒体对贵州遵义39岁无腿外卖员高龙友的“励志”报道引发公众强烈反弹。网友批评这种宣传是将“制度缺陷包装成个人奋斗神话”,指出其本质是社会保障漏洞、残疾人就业支持薄弱以及“平台算法把人当工具”的体现,而非值得赞美的“正能量”。评论认为,这种叙事是“毒鸡汤”,会拉低全社会劳动者的底线,并质疑一个社会若以“残疾人拼命工作”衡量正能量,其运行逻辑已出现问题。
分析:
它直接涉及人工智能(AI)在社会层面引发的“社会影响与伦理风险”。新闻中明确指出“平台算法把人当工具”和“平台用‘算法最优’榨取外卖员的每分每秒”,这体现了AI算法在劳动就业领域可能导致的剥削、不公以及对社会保障体系的冲击,并可能“拉低全社会劳动者底线”,符合高价值标准中关于AI引发“失业、降薪、算法歧视、偏见、隐私泄露等社会问题,或造成社会撕裂与信任危机”的描述。
正文:
美团女外卖员去小城市送外卖三个月,就买了一台15000元的相机,还说“送外卖可以欣赏沿途风景”这件事刚刚过去,然而另一个外卖员的出现,就被一些权威媒体和大公司捧上了天。
近期贵州遵义39岁无腿外卖员高龙友的视频引发全网骂战,媒体用"灵魂强大""一切皆有可能"等标题赞美其"自强不息",但网友愤怒指出:
这不是励志,是把制度缺陷包装成个人奋斗神话
。
网友们指出,把“苦难”当营销燃料,缺德:
残疾人送外卖,本质是社会保障网有漏洞、残疾人就业支持体系薄弱、平台算法把人当工具。但一些人和媒体却把这种无奈美化成“正能量”,把社会上一些人该背的锅,甩给个人“努力不够”。
这相当于有人摔进坑里骨折了,他们不去怪挖坑的人,反而拍掉坑里的人忍痛爬行的视频说“看,多励志!”——这不是缺德是什么?
“一切皆有可能”是当代毒鸡汤:
一个失去双腿的人要靠用滑板送餐、靠爬楼梯送外卖才能生存,这首先暴露的是:为什么我们的社会没有给他更安全、更有尊严的就业选择?平台用“算法最优”榨取外卖员的每分每秒,却把交通事故、客户差评的风险全甩给骑手。
这时候鼓吹“一切皆有可能”,其实就等于说“你失败,其实是你不想方设法把自己的困境变成可能的希望!不信你看,别人缺腿都能送外卖!”
这个视频还偷偷换了一个概念:
就是把“企业该提供的合理保障、社会该完善的托底制度”这类根本性问题,扭曲成了“只要你拼命,残疾也能赢”的成功学。
这会导致更多健全工人被骂:“人家没腿都这么拼,你抱怨什么?” 结果是全社会劳动者底线一起被拉低。
"如果一个社会用'残疾人拼命工作'衡量正能量,而不是用'残疾人活得从容'来衡量,那这个社会的运行逻辑可能已经出问题。"
这场舆论风暴本质是公众觉醒的标志:
人们终于意识到,赞美苦难的人往往是想延续苦难的人
。当媒体还在制造"感动中国"的叙事时,大众已经开始追问背后的结构性问题——这才是社会进步的真正信号。
主题分类:
社会影响与伦理风险
新闻 19: 拼手速抢兼职,年轻人迷上“抢班”
来源: 新浪微博 - 自媒体
主题: 深圳年轻人灵活就业“抢班”现象、其社会经济动因、对AI技术替代的担忧及其带来的挑战。
摘要:
深圳的年轻人正积极参与“抢班”现象,为咖啡店等灵活兼职岗位激烈竞争,以获取高时薪和日结工资。这种趋势由深圳高昂的生活成本、年轻人对即时经济回馈的需求以及对AI技术可能替代工作的担忧所驱动。咖啡企业也通过这种模式实现低成本扩张。然而,“抢班制”也暴露出兼职人员缺乏系统培训、工作时长可能超标以及社会保障缺失等问题。文章指出,灵活就业将持续发展,企业需平衡效率与员工福利,年轻人则需理性选择兼职以结合长期职业规划。
分析:
它直接涉及AI技术可能引发的社会影响。正文中明确指出,“深圳30岁以下职场人中,超过40%担心自己在未来五年内会被人工智能等技术替代”,这表明AI技术带来的“失业”或职业焦虑是年轻人选择灵活就业、参与“抢班”的重要动因之一,符合“社会影响与伦理风险”的高价值标准。
正文:
早高峰的深圳Manner咖啡店内,兼职咖啡师小陈刚完成三小时的班次,手机上就收到了79.2元转账,这是即时工资到账的通知。而两天前他还在为抢到这个班次定闹钟、无数次刷新小程序,这份兼职是他用堪比抢演唱会门票的手速换来的。
在深圳繁华的商区,这一品牌的咖啡门店中,早上8点到11点的兼职时薪能达到28元,且工资日结。这比同一区域的星巴克25元和普通奶茶店22元的时薪更有优势。这种即时的金钱回馈和灵活的工作安排,正吸引着这座年轻城市中越来越多的人加入“抢班大军”。
网络截图。抢班竞争激烈,一位难求。
咖啡店兼职,3秒抢光
兼职咖啡师岗位已经变成了一种需要定闹钟、拼网速、攒人品才能获得的稀缺资源。系统开放瞬间,班次通常在3秒内全部“变灰”被抢光,这种场景不亚于抢购热门演唱会门票。
根据《2025年灵活用工平台就业发展报告》,我国灵活就业人员已超过2亿人,差不多每7个中国人里就有1个人正在以某种“灵活”的方式工作。其中,24岁以下的年轻人占比近六成,成为这种新型就业模式的主力军。
深圳作为中国最年轻的一线城市,公开数据显示,常住人口中15-59岁人口占比高达79.53%,这也为兼职岗位的火爆提供了庞大的人群基础。
在深圳的年轻人中,同时打多份工已经成为一种生存策略。据调查,超过30%的深圳青年拥有不止一份收入来源,其中兼职咖啡师成为受欢迎的选择之一。在某社交平台上,总能看到新手小白怯生生询问:“咖啡师不需要有从业经验吗?”得到的回答往往是,“上手很快,很容易学的。”还有人分享自己的经历说,最初的工作就是负责加加冰块、给杯子贴标签、打包,堪称“有手就会”。
“短平快”就业
年轻人口结构是首要因素。在已公布的数据中,深圳常住人口平均年龄仅为32.5岁,是全国人口最年轻的大城市。有调查显示,95后人才吸引力城市中,深圳排名第一,北京、上海、广州、杭州排在其后。深圳仍是年轻群体最想去的城市之一。这个庞大的年轻群体既有消费能力,也有兼职需求,形成了一个自循环的“消费-
就业”闭环。
高生活成本下,“搞钱”文化是深圳年轻人参与抢班的重要动力。深圳房价、物价长期领先全国,巨大的收支缺口迫使年轻人寻找更多收入来源。灵活性是另一个关键因素。以Manner为例,兼职每周仅需出勤2-4天,工作时间灵活,早8-11点、午12-15点等时段可自由选择。这种“短平快”的就业模式完美契合了深圳年轻人快节奏的生活方式。深圳对灵活用工的包容政策为这种模式提供了土壤。不同于一些城市对非传统兼职形式的一刀切管理,深圳正在探讨如何规范而非禁止这种新型就业形式,这降低了年轻人尝试兼职的门槛。
咖啡企业“低成本快速扩张”的策略也直接推动了兼职岗位需求。对比数据显示,Manner人工成本占比仅为12.5%,远低于星巴克等头部品牌的30%以上。这就要求门店日营业额需达到6000元以上才会配置两名店员,导致单店人力紧张,进一步增加了对兼职员工的需求。为保持低成本,咖啡店将兼职岗位细分为不同等级:普通咖啡师时薪25元左右,而通过考核的“星级咖啡师”时薪可达28元,且享有优先抢班特权。这种差异化激励机制既控制了成本,又鼓励兼职者长期稳定地在同一门店工作。
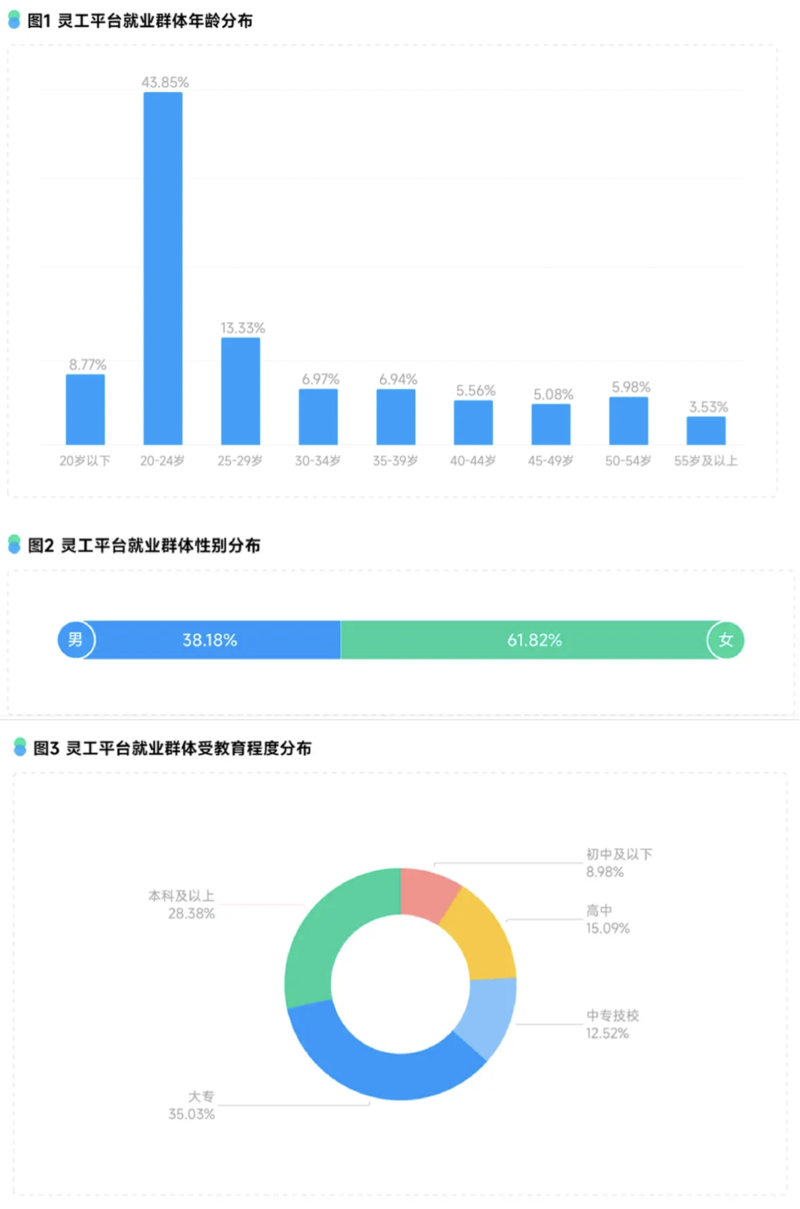《 2025
年灵活用工平台就业发展报告》显示,我国 灵活就业人员中,24 岁以下的年轻人占比近六成,成为这种新型就业模式的主力军。
即时回馈带来安全感
在不确定的经济环境下,“即时获得”成为年轻人重要的心理需求。咖啡店的日结模式恰好满足这种心理——工作完成后几小时内,工资就能到账,这种即时回馈带来安全感。
深圳年轻人还面临着职业发展的多重压力。据统计,深圳30岁以下职场人中,超过40%担心自己在未来五年内会被人工智能等技术替代。这种职业焦虑促使他们通过兼职增加收入来源,减少对单一工作的依赖。“零门槛”的咖啡师工作为年轻人提供了暂时的职业避风港,相比需要专业技能的岗位,Manner兼职只需进行简单培训即可上岗,成为年轻人在职业过渡期的理想选择。
年轻人还通过这种兼职体验不同职业角色,许多参与抢班的年轻人本身有正式工作,他们通过咖啡师兼职暂时逃离日常工作的压力,在相对轻松的环境中获取新的体验——首先,日结模式更符合年轻人的现金流需求;其次,咖啡店工作环境更清爽体面,“咖啡师”头衔也自带文艺滤镜,符合年轻一代的职业审美;最后,除了时薪高于许多同类岗位,咖啡店兼职还能获得每日一杯的免费员工饮品,综合报酬更具吸引力。
但是,任何事物都具有两面性。抢班制也存在着不可回避的问题。咖啡店为节省成本,几乎不对兼职员工进行系统培训,将培训压力转嫁给全职员工。在高峰期,经常出现一名全职员工带领一名新手兼职的情况,大大增加了工作强度。法律方面,根据《劳动合同法》,非全日制用工一般平均每日工作时间不应超过4小时,每周工作时间累计不超过24小时。但在实际操作中,许多兼职者一天内连续抢多个班次,工作时长可能超出法律规定。福利缺失是另一个关键问题,企业使用兼职员工可以省去社保和长期福利支出,这是“抢班制”降低企业成本的核心。但对于劳动者而言,这意味着缺乏基本的社会保障。
寻找微妙的平衡
未来,这种年轻人中流行的“抢班”现象很可能还会持续存在。随着经济环境的变化,灵活就业已成为全球趋势,据预测,到2030年,中国的灵活就业人员可能达到4亿人,占劳动年龄人口的一半左右。在深圳这样的创新型城市,灵活用工模式可能会更加多元化。未来可能出现更多类似“抢班制”的平台,涵盖更多行业和岗位,如设计、编程、文案等知识型工作也可能采用这种模式。
企业将不得不面对用工模式转型带来的管理挑战,即如何在效率与员工福利之间找到平衡点,成为企业可持续发展的关键。据悉,已经有深圳企业开始探索“灵活就业+基本保障”的新型用工模式。
对于年轻人而言,面对“抢班潮”,需要更加理性地选择。优先考虑那些能够提升技能的兼职,而非纯粹的体力劳动,将短期兼职与长期职业规划相结合,才是明智之举。
夜色渐深,小陈结束了兼职咖啡师的工作,走出店门。他需要在凌晨再次打开手机,为后天早晨3小时的班次再拼一次手速。同样的场景也在深圳数百家咖啡门店同步上演。这座城市从不缺少梦想,但梦想的兑现方式正在悄然改变。年轻人一边刷着“不想上班”的表情包,一边在兼职平台抢班厮杀。在这场不见硝烟的“抢班战争”中,每个参与者都在寻找着工作与生活之间微妙平衡的可能。
读特&晶报记者 李岷/文
主题分类:
社会影响与伦理风险
新闻 20: AI时代来临,普通人如何逆风而行?掌握五大策略,迎接未来新机遇
来源: 今日头条 - 自媒体
主题: 普通人在AI时代的应对策略与个人发展
摘要:
该新闻探讨了在AI时代普通人如何应对挑战并抓住机遇的策略。文章强调要理性认识AI、持续提升技能(包括数字技能、创造力、批判性思维和软技能)、善用AI工具提升效率、调整积极心态迎接变革,并积极参与AI伦理和政策讨论,以确保AI健康发展。核心在于通过学习和适应,在AI浪潮中找到个人定位。
分析:
该新闻具有价值,因为它直接讨论了AI技术发展带来的“失业危机”和“焦虑”等社会影响,并提出了“关注AI相关的伦理、政策讨论”以及“推动行业规范”的建议。这些内容与高价值标准中的“社会影响与伦理风险”维度高度相关,特别是涉及AI引发的“失业”等社会问题。
正文:
随着人工智能(AI)技术的飞速发展,全球正迎来一场深刻的变革。从自动驾驶、智能客服到内容生成、医疗诊断,AI的触角已渗透到我们生活的方方面面。面对这股席卷而来的浪潮,许多普通人心中充满焦虑:我会被取代吗?我该如何适应这个全新的时代?其实,危机与机遇并存,只要掌握正确的应对策略,每个人都能在AI时代找到属于自己的位置。
一、理性认识AI,避免盲目恐慌
首先,最重要的是要以科学的态度看待AI。很多人担心“机器人会取代我”,甚至出现“失业危机”的恐慌。这种担忧虽有一定的合理性,但也容易走向极端。实际上,AI是一种工具,它的出现是为了提升效率、解放人类,让我们从繁琐的工作中解放出来,专注于更具创造性和价值的任务。
因此,普通人应当理性认识AI的本质和发展趋势,了解哪些岗位可能受到影响,哪些岗位会因AI而新生。只有这样,才能在变革中保持清醒的头脑,做出正确的应对措施。
二、不断提升技能,打造不可替代的核心竞争力
AI的崛起带来了岗位的变动,但也催生了许多新兴职业。面对未来,最稳妥的应对之道,就是不断提升自身的核心技能。
具体来说:
掌握数字技能
:学习数据分析、编程、AI基础知识,为未来职业布局打下基础。
培养创造力和批判性思维
:AI虽能模仿逻辑,但创新和批判仍是人类的优势。
发展软技能
:沟通、情感理解、团队合作等软技能,是机器难以取代的。
终身学习
:利用网络课程、培训班不断更新知识,保持竞争力。
只有不断学习,才能在变革中站稳脚跟,甚至抓住新机遇。
三、善用AI工具,提升工作效率
在日常工作和生活中,善用AI工具可以让我们事半功倍。例如,利用智能写作软件提升内容产出,用AI辅助的设计工具改善视觉效果,或者通过数据分析工具优化决策。
这不仅能提升个人效率,也能增强竞争力。比如,内容创作者可以借助AI生成辅助工具,快速产出优质内容;企业可以用AI进行客户分析,精准营销。掌握这些工具,成为自己的“加速器”,在职场中更具优势。
四、调整心态,积极迎接变革
变革带来不确定性,难免引发焦虑。普通人应保持积极心态,把变化看作成长的契机。
认清AI是助力而非威胁
:它可以帮我们解放繁琐工作,让我们专注于更有价值的事情。
建立安全感
:不断学习新技能,增强自我价值感,减少对未知的恐惧。
合理规划未来
:提前制定职业规划,积极适应变化,减少焦虑。
保持弹性
:勇于尝试新事物,善于从失败中学习,逐步适应新的环境。
五、参与公共事务,推动行业规范
普通人不应只是被动的接受者,也应积极参与AI相关的伦理、政策讨论。关注行业动态,表达自己的观点,推动AI的健康发展。
你可以:
关注政策法规,了解AI伦理问题;
参与社区讨论,分享自己的看法;
学习相关知识,成为推动行业规范的力量。
只有共同努力,才能确保AI技术造福人类,而非带来灾难。
总结:把握机遇,迎接未来
AI的全面崛起,既带来了挑战,也带来了前所未有的机遇。普通人应理性认识、不断学习、善用工具、调整心态、积极参与,才能在变革中找到自己的位置。
未来已来,关键在于我们是否准备好迎接。只要保持学习的热情和积极的心态,每个人都能在AI时代找到属于自己的光明未来。
主题分类:
社会影响与伦理风险
新闻 21: 无标题
来源: 新浪微博视频 - 自媒体
主题: AI幻觉对电子出版物错误责任归属的影响
摘要:
新闻讨论了纸质出版和电子出版在错误责任归属上的差异,指出电子出版中出现的错误,如“AI幻觉”,使得责任难以明确,并暗示了纸质出版的衰落。
分析:
该新闻具有价值,因为它明确提到了“AI幻觉”这一AI技术特有的现象,并探讨了其在电子出版领域可能导致的“再也找不到一个具体责任人”的问题。这直接关联到AI内容生成或处理的可靠性、透明度以及责任伦理,符合“社会影响与伦理风险”的高价值标准。
正文:
如果“错误多”说明纸质出版不行了,那么电子出版怎么样呢,纸质书刊错了还能抓住作者和责编,明确是他们的责任,电子书/数据库错了,可以说转码错了、识别错了、网络问题、设备问题、版本更新问题、AI幻觉……再也找不到一个具体责任人了//@尚書蘭臺
,现在出问题的书反而好多是十几二十年前甚至更早初版,那会才是群魔乱舞啥都敢出//@那罗陀_银子
,中华书局也这样了。纸质出版真的日薄西山了……
主题分类:
社会影响与伦理风险